




この記事は CARTA TECH BLOG アドベントカレンダー2024 の 12/6 の記事です!
株式会社CARTA MARKETING FIRMのDSPでエンジニアをしているmarching-cubeと申します。
ONNXランタイムへの移行
最近、本番環境のリアルタイム入札(RTB)サービスをONNXランタイムフレームワークに移行しました。 CARTA MARKETING FIRMが提供する入札モデルは、ロジスティック回帰や事前に訓練されたルックアップテーブルなど、小規模であっても慎重に設計された推定量を活用する機械学習推論サービスです。モデルサイズは最大で100KB未満で、一部のモデルは5KB程度の小さなものもあります。
人気のある深層ニューラルネットワーク(メガバイト単位の埋め込みデータを持つもの)と比較すると、まさに「小型」です。そのため、追加のフレームワークによるオーバーヘッドなしでネイティブコード(Kotlin)による効率的な実装が容易でした。実際のところ、すべてのオーバーヘッドを考慮すると、ONNXランタイム(C++ライブラリ)が既存の実装のレイテンシを改善できるとは思えません。
それでも、試してみるべき理由がいくつかあります。
期待すること
#1: コードの重複とバグの削減
現在、我々は本番環境でカスタムのロジスティック回帰コード(ユニットテストを含む)を運用しています。 学習環境(Python)と推論環境(Kotlin)の間で、特にデータ前処理においてコードの重複が発生しています。 この重複は運用とテストを煩雑にし、実装の差異が原因で難易度の高いバグを引き起こすことがあります。
ONNXを使用することで、ほとんどのカスタムコードを排除し、環境間で推論および前処理のロジックを共有できるはずです
#2: 線形モデルを超えて、迅速に実験出来る
ロジスティック回帰は上手く活用できましたが、より複雑な計算アーキテクチャを試す価値もあります。 現状では、このような試行には大幅な変更とリファクタリングが必要です:
- ネイティブ実装のほとんど(推論とトレーニングの両方)を書き直す
- 複数の新しいフレームワークを連携させる(将来的な運用も含む)
ONNXを用いると、理想的には機械学習モデルの交換が本番コードを変更することなくデプロイ可能なはずです。
#3: 将来の保護
ONNXを推論環境と学習環境の間の抽象レイヤーとして配置することで、両者の結合をほとんど取り除くことが期待できます。 たとえKotlinで実装されている推論サービスを他の言語に(部分的にでも)切り替えても、ONNXアーティファクトはそのままで使用し続けることが可能です。
同様に、いくつかの単純なアルゴリズム(例えばルックアップテーブル)を早めにONNXモデルで置き換えることで、 将来的により良い実装に簡単に置き換えることができます。
期待すべきでないこと
#1: 推論性能の向上
高パフォーマンスを保証することは難しく、ONNXも万能な解決策ではありません。単純なネイティブ(Kotlin)実装が、 より高速なONNX環境を実現するとは思えません。
#2: GPU推論
GPUによる推論を気軽に設定できるのは良いことですが、実際にはまだそのような使用ケースがありません。 小型モデルではCPUの使用率がそれほど高くないため、全体的なボトルネックは主に他の部分(データベースアクセスなど)にあります。
最初の(失敗した)試み
コンセプト実証のためには、ONNXへの移行を少ないステップで完了させることができます:
- 既存のモデル学習コードと前処理を
sklearn.Pipelineに統合します。 sklearn.Pipelineオブジェクトをskl2onnxライブラリを使ってONNXに変換し、アーティファクトをS3やGCSにアップロードします。- 最新の
onnxruntimeライブラリをプロジェクトに追加します(Linux互換性の問題に注意してください)。 - 既存のカスタム推論実装を標準の
onnxruntimeコードに置き換えます。 - リリースの準備をする
設計から本番展開までのすべての作業は、1週間から2週間で達成可能です。 しかし実際には、ONNXの統合を追加するよりも、既存のコードをリファクタリングするのに非常に多くの時間を費やしました。
実装は簡単ですが、リリース後の結果が期待外れになることもあります。 例えば、単一のロジスティック回帰を置き換えたところ、サービスのレイテンシが10ms以上増加しました。 しかも、この増加はビジネス上の改善が何もない状態で発生しています。
パフォーマンス最適化
レイテンシのボトルネックについて詳しく見ていきましょう。
我々の推論サービスの実装はKotlin(JVM)でネイティブに書かれていますが、ONNXランタイムフレームワークはC/C++で実装されています。 このため、JVMは多数のJNI呼び出しを行っています。個々の呼び出しにはあまり負荷はかからないと思いますが、 不必要なループが繰り返されることで、最終的に負荷が蓄積する可能性があります。
これらの呼び出しを視覚化するために、単純化したシーケンスグラフを提供します。
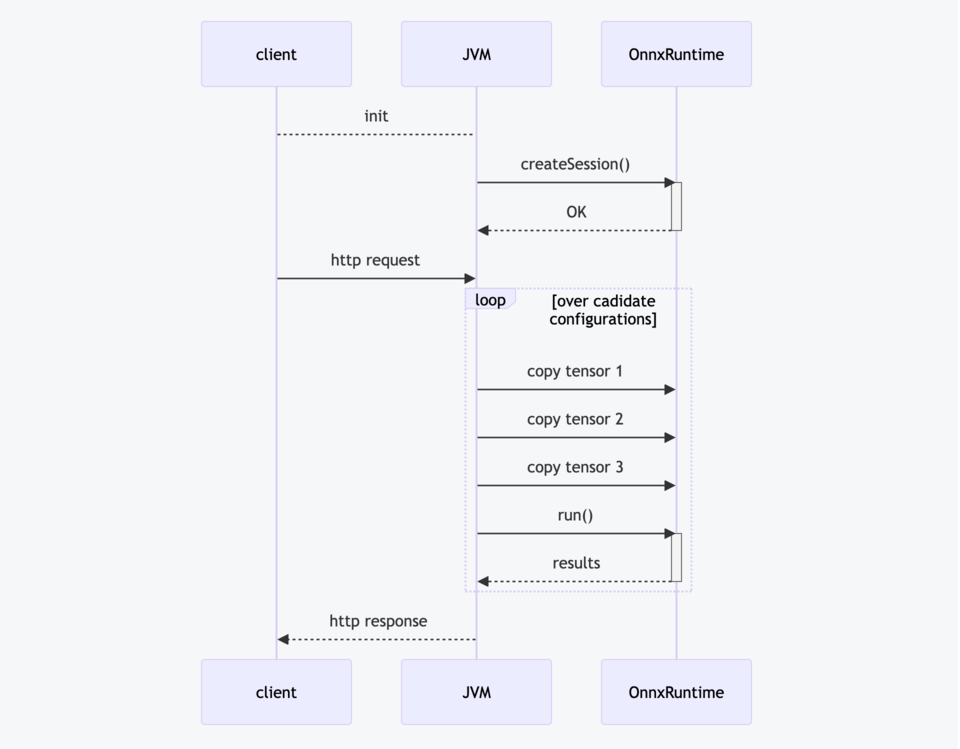
主なポイント:
createSession(): ONNXデータをメモリにロードし、内部設定と初期化を行います。これは、サービスの起動時に一度だけ行われる重い操作です。forループ: すべての候補データに対して推論関数を一つずつ呼び出していますが、明らかに無駄な繰り返しです。特に、ONNXランタイムの呼び出しが追加のJNIオーバーヘッドとともに発生しています。データコピー: ONNXランタイムへのデータコピーには時間がかかるようです。ネイティブコード(Kotlin)では相当なオーバーヘッドはありません。run(): ONNXモデルを実行するため、モデルがシンプルで小さいほど、この呼び出しは速く終了するはずです。
これらの各ステップには最適化すべき点があります。
改善案
#1: ベクトル化
こういったKotlinのforループからONNXランタイムを実行するのは、大きなボトルネックになりそうです。
// 既存の実装 for (data in candidates) { val tensors = copyTensors(data) // shape=(1,K) session.run(tensors) } // 改善された実装 val tensors = copyTensors(candidates) // shape=(N,K) session.run(tensors)
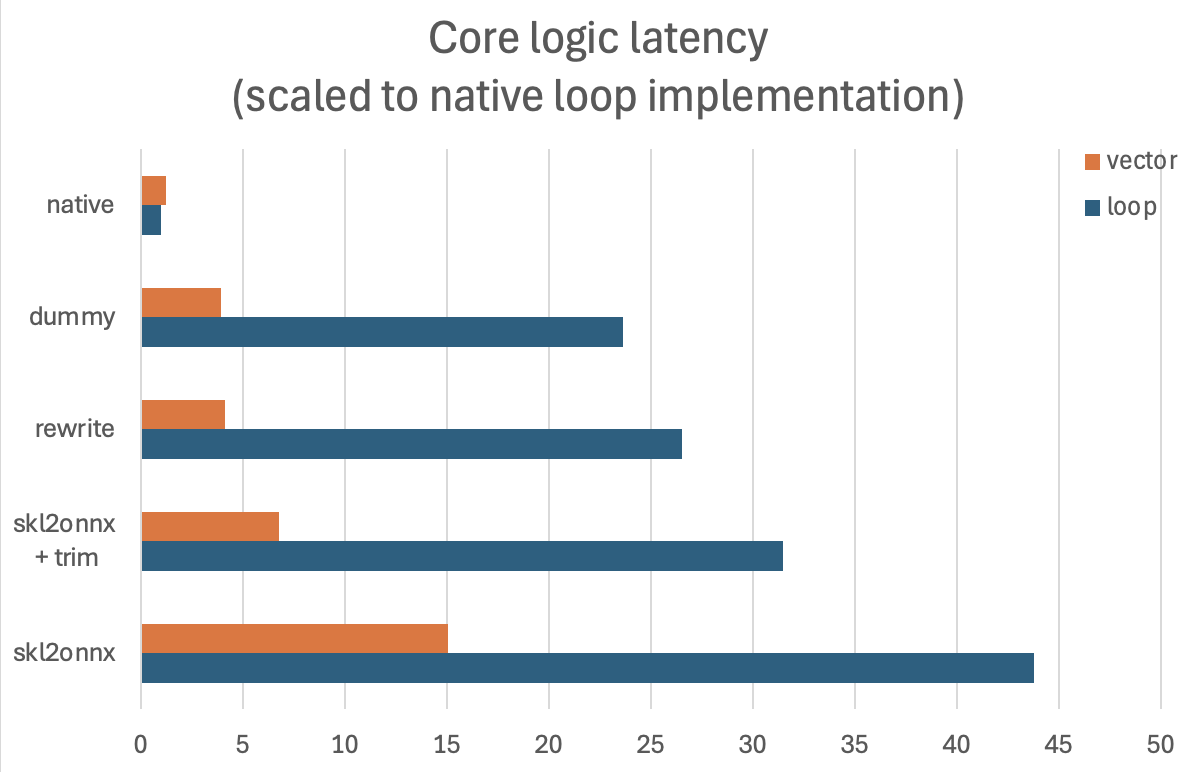
ベクトル化された実装により、性能が大幅に向上します(主に不要なJNI呼び出しを削減するため)。 既存のコードベース全体をリファクタリングするのは容易ではありませんが、それだけの価値があるようです。 初期の推定では、実行時間が約2.9倍短縮されることが期待されています。
#2: 慎重に最適化されたONNXグラフ
さらなるパフォーマンスのデバッグを行った結果、skl2onnxの出力が最適ではないことが分かりました。
具体的には、sklearnのOneHotEncoderをONNXの同等の操作に書き換え、スパースなベクトルをLinearRegressionに渡していましたが、
この方法は最適ではありません。代わりに、LabelEncoderとSumをうまく利用すると、パフォーマンスが向上します。
# skl2onnxの出力 sparse_vectors = OneHotEncode(input) # 各インプットに対して probability = LinearRegression(sparse_vectors) # 手動で書き直したら dense_vectors = LabelEncoder(input) # 各インプットに対して probability = Sigmoid(Sum(dense_vectors))
さらに、ゼロ係数を削除(トリミング)した結果、生成されたONNXグラフはベクトル化による改善に加えて3.6倍速くなりました。
#3: インプットレイアウトの改善
一方で、少なくとも現時点では、テンソルコピーのコードを改善する良い方法を見つけることができませんでした。
ベクトル化された各特徴を個別のONNX入力としてロードしており、これにより、追加のマッピング情報なしで実行時に必要な特徴と ONNX入力を判断できます。これらを単一の高次元入力テンソルにまとめることで、パフォーマンスの向上(JNI呼び出しの減少など) を期待しましたが、ローカルテストではこれが確認できませんでした。
最終結果
すべての最適化を適用した結果、オフラインパフォーマンステストで10倍以上の改善が見られました。
本番展開では、1〜2msのオーバーヘッドが予想されます。
ONNXでの作業のヒント
学んだこと
- パフォーマンスと正確さの両方を測定できるオフラインテスト環境を準備することは重要です
- 細かなパフォーマンスバグ(スローハッシュ化など)は発生しやすく、単体テストが不足している部分でのリファクタリングは危険です。
- JVMは実行されたコードを積極的に最適化するため、実行時の測定値には注意が必要です。
- オフラインの結果が良好な場合は、必ずこの実装をステージングまたは本番環境でのオンライン実験で確認します。
- ネイティブループ内(Kotlinのfor文など)で推論を実行しないようにします。可能であれば、データをベクトル化します。
- 強い正則化をかけられたモデルは、ゼロ係数で満たされる場合があります。例えば、ロジスティック回帰では、うまくトリミングすることで推論が速くなる可能性があります。
- ONNXグラフを慎重に書き直すことで、場合によってはパフォーマンスの改善につながります。
- データのコピー手法も慎重に検討します。テンソルをキャッシュまたはグループ化するような設計を考慮すると良いでしょう。
追加のヒント
- ONNXのProtobufスキーマとOpSet仕様をよく理解することが重要です(参考:https://github.com/onnx/onnx/blob/main/docs/Operators.md)。
float32演算は小さな数値誤差を引き起こし、正確なモデル比較を多少難しくします。ただし、この点についてはあまり心配する必要はないでしょう。- JVMにおいても、ONNXランタイムがメモリリークを引き起こす可能性があるため、すべてのテンソルの
close()を必ず忘れずに行ってください。 - IR(ONNX Intermediate Representation)の互換性はOpsetの互換性とは異なります。必要であれば、新しいONNXモデルを古いonnxruntimeでも使用できます。
- サンプルONNXモデルは簡単に作成でき、ベンチマークの基準点として使用できます。
- データの辞書(ルックアップテーブル)はONNXの
LabelEncoderで簡単に表現できます。ただし、float64の出力がないことは覚えておいてください。 - 長いテンソル(例えば、次元が10000など)をテストする際に、いくつかの異常なパフォーマンス挙動を経験しました。代表的なパラメータを調べてテストを設定することが重要だと思います。