




TL;DR
CARTA MARKETING FIRMのデータサイエンスチームは、8年間にわたり機械学習基盤を進化させてきました。Luigi、AWS SageMaker、Prefectと変遷する中で、「データサイエンティストが最も付加価値を生み出す部分に集中し、時間を費やすことができる基盤」という目標に着実に近づいています。
- Luigiでは開発環境構築や運用負荷が高く、柔軟性に欠けていました。
- SageMakerではインフラ構築の複雑さやStep Functionsの制約が課題でした。
- Prefectの導入により、Pythonのみでインフラからバッチ処理まで記述可能になり、A/Bテストの実施が容易になりました。また、ログ監視の一元化により運用効率が大幅に向上しました。
この進化を通じて、データサイエンティストの生産性と施策の実験サイクルが大幅に改善されました。
概要
CARTA MARKETING FIRMのデータサイエンティスト、クリスです。自社の広告配信アドプラットフォーム(DSP)で機械学習を活用した配信ロジックの開発に携わっています。
本記事では、CARTA MARKETING FIRMのデータサイエンスチームが過去8年間で経験した機械学習基盤の変遷を詳細に解説します。Luigiを使用した初期の基盤から、AWS SageMakerを経て、現在のPrefectベースの基盤に至るまでの道のりを紹介します。
各段階で直面した技術的課題とその解決策、そしてチームの成長や組織の変化が基盤選択にどのように影響したかを具体的に説明します。この経験を共有することで、同様の課題に直面している他のデータサイエンスチームの方々に有益な洞察を提供できればと思います。
理想とする機械学習基盤の姿
CARTA MARKETING FIRMのデータサイエンスチームが理想とする基盤は、データサイエンティストが最も付加価値を生み出す部分に集中し、時間を費やすことができる基盤です。
現在はPrefectをベースとした機械学習基盤に落ち着いていますが、この選択に至るまでには、さまざまな試行錯誤がありました。
下記の図は、一般的な機械学習基盤の要素を示しています。この図では、データサイエンティストが実験を行う際の核心部分、例えばモデルのトレーニングやKPIの測定といった要素(黒いボックス)が強調されています。これらは、データサイエンティストにとって最も楽しく、また価値を生み出す部分です。
しかし、実際にそのコードを本番環境に移行する際には、図に示された多くの「隠れた」要素(その他のボックス)を実装し、対応する必要が生じます。この「隠れた」要素は、データパイプラインの管理、モニタリング、デプロイメント、セキュリティ対策など、多岐にわたります。
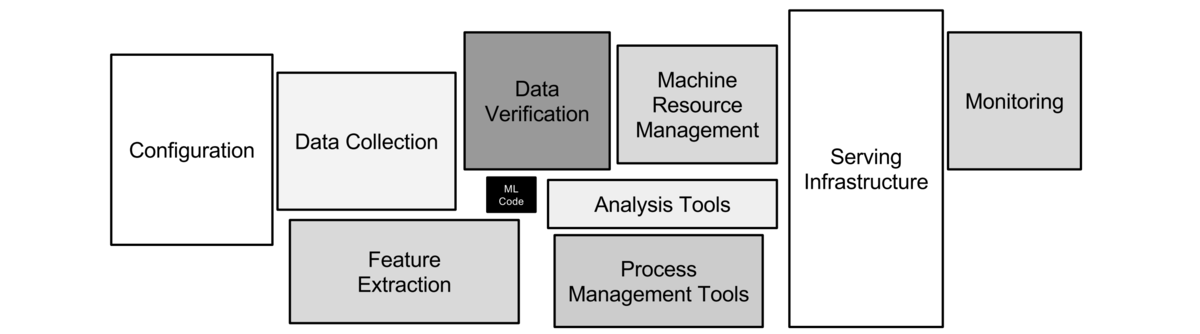
出典: Hidden Technical Debt in Machine Learning Systems
これが、多くのデータサイエンティストが、施策のコードを本番環境にデプロイする際に直面する大きな課題です。結果として、彼らは最も注力すべき核心部分に時間を費やすことができず、むしろ周辺の実装や対応に多くの時間を割かなければならない状況が発生しています。CARTA MARKETING FIRMも例外ではありませんでした。
この課題を克服し、データサイエンティストが本来の業務である核心部分に集中できるようにするためには、効率的かつ統合された機械学習基盤が不可欠です。
次に、弊社のデータサイエンスチームがどのようにして現在の基盤にたどり着いたのかをご説明いたします。
Luigiベース基盤の時代 (2015年〜2021年)
チームの状況
データサイエンスチームは、データパイプラインの構築・運用から、機械学習モデルの開発・導入まで、幅広い業務を担当していました。そのため、チームは非常に多岐にわたる責務を担っていました。
この広範な責務を遂行するために、チームにはソフトウェアエンジニアリングの知識に加えて、機械学習やデータサイエンスに関する深い理解を持つことが求められていました。そのような幅広い知識を持つメンバーがパイプライン開発・運用を担当する主要なメンバーとなっていました。
Luigiパイプラインの導入背景
当初、LuigiはS3に保存されたログデータをBigQueryのテーブルに取り込むETLパイプラインとして導入されました。 その後、機械学習モデルのプロダクト統合が決定された際、以下の理由からLuigiが継続して使用されることになりました:
- 既存の知識と経験: チームがすでにLuigiの使用に慣れていた
- 学習コストの最小化: 新しいツールの導入による学習コストを避けられた
- 柔軟性: ETLと機械学習タスクの両方をカバーできる汎用性
アーキテクチャ図
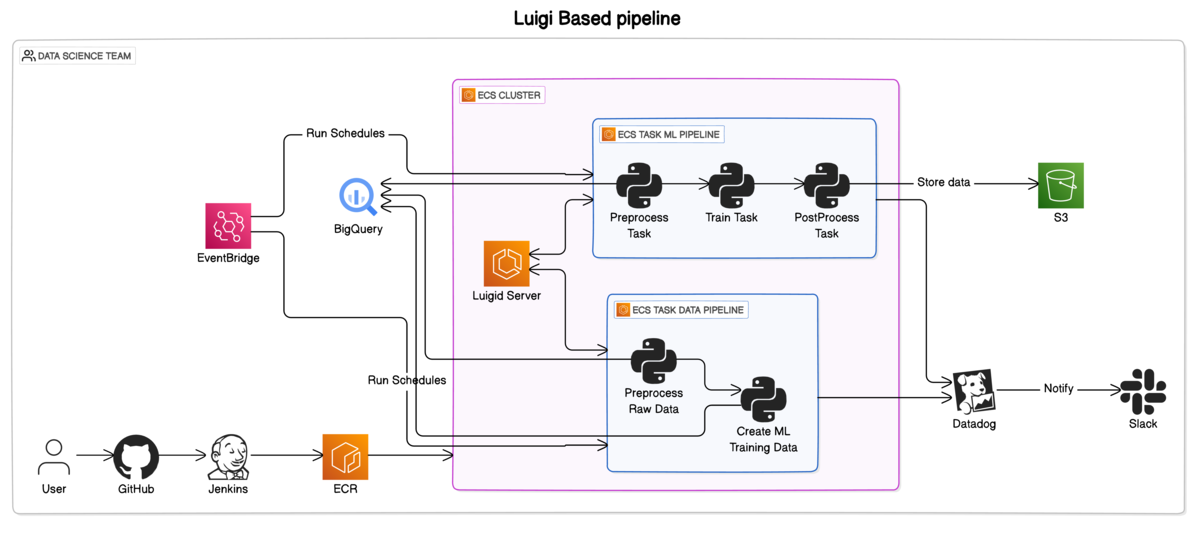
Luigiパイプラインの特徴
Luigid Server(タスクスケジューラー)によるタスク管理
- LuigiのタスクスケジューラーをECSサービスとして立ち上げ、自分たちで運用
- タスクはECSタスク内で実行
CI/CDパイプライン
- GitHubとJenkinsを活用したCI/CDパイプラインを構築し、コードの品質向上とデプロイの自動化を実現
監視とログ管理
- Datadogによるモデルのメトリクス監視
- LuigiのUIでログを確認
データウェアハウス
- データウェアハウスとしてBigQueryを採用し、大規模なデータ処理を効率的に実行
- 高速なクエリとスケーラブルなデータ分析が可能
インフラ管理
- Terraformによる一貫性のあるインフラ構築
- 本番環境のみの運用(ステージング環境なし)
Sagemakerベース基盤への移行(2022年〜2023年)
チームの変遷とパイプライン刷新のきっかけ
2022年にデータサイエンスチームは、大きな転機を迎えました。主要メンバーの退職に伴い、データエンジニアが新たにチームに加わりました。この人員変更が、私たちのパイプライン刷新の重要なきっかけとなりました。
当時、チームは下記の状況でした。
- 新卒や経験の浅いデータサイエンティストが主なメンバーでしたが、迅速な施策の試行が依然として求められていた
- しかし、既存の基盤システムへの理解が不十分だったため、その運用に多くの時間を取られていた
- 結果として、新しい施策を試すまでに予想以上の時間がかかっていた
これらの問題を解決するため、チーム内の責任分担を以下のように再編成しました。
データサイエンティスト
- 施策の提案、ロジックの開発
- 機械学習パイプラインの開発と運用を担当
データエンジニア
- データパイプラインの開発と運用を担当
この役割分担により、各メンバーが自身の専門分野に集中し、最大限の能力を発揮できる環境を整えることが私たちの当面の目標となりました。
まず、データエンジニアがデータパイプラインの刷新を行い、データサイエンティストの負担を大幅に軽減してくれました。この功績により、データサイエンティストも長年認識していたLuigiベースのパイプラインの課題に取り組む余裕が生まれました。
そこで、私たちは機械学習パイプラインの改善に着手することにしました。
Luigiパイプラインの具体的な課題
長年Luigiパイプラインを運用してきた中で、以下のような問題点が見えていました。しかし、木こりのジレンマと同様に、目先のタスクに追われており、このパイプラインを変える余裕がなかなかありませんでした。
- データサイエンティストの責務範囲が広い
- A/Bテストまでのリードタイムが長い
- 開発体験の問題
データサイエンティストの責務範囲が広い
データパイプラインと機械学習パイプラインの両方の開発・運用を担当していました。ロジック開発や施策の効果検証も担当していました。
A/Bテストまでのリードタイムが長い
本番環境にA/Bテスト用のコードを都度追加・削除する必要がありました。施策を試行するたびに本番環境のコードを変更する必要があり、既存コードへの深い理解が常に求められたため、実験までのリードタイムが長くなっていました。
開発体験の問題
ローカル環境でパイプラインが動作せず、チームメンバーは本番環境と同じ構成で立ち上げたEC2インスタンス上での開発が標準となっていました。Luigiの独特な記法が学習コストを増大させ、新しいメンバーにとって扱いづらかったです。動作確認時にはタスクの依存関係を準備する必要があり、初心者には難解でした。UIから個別のタスクを再実行することができず、障害時の対応が複雑化していました。
SageMakerの導入理由
上記の課題を解決するために、さまざまな機械学習基盤を模索しました。大手クラウドベンダーのサービスを利用することで、安心感を得たいという考えもあり、複数の選択肢に迷いました。
最終的には、AWS上で動いている既存システムとの親和性を考慮し、SageMakerを採用することに決定しました。
さらに、AWSのプロトタイピングプログラムを活用できたことも、SageMakerを選んだ大きな理由の一つです。
当時のデータサイエンスチームは主にジュニアメンバーで構成されており、0から1を生み出すことに対するハードルが高かったため、プロトタイピングエンジニアに相談しながら実装を進められた点は非常に助かりました。
もし、チームが同じような状況ならぜひプロトタイピングプログラムを活用することをおすすめします。
アーキテクチャ図
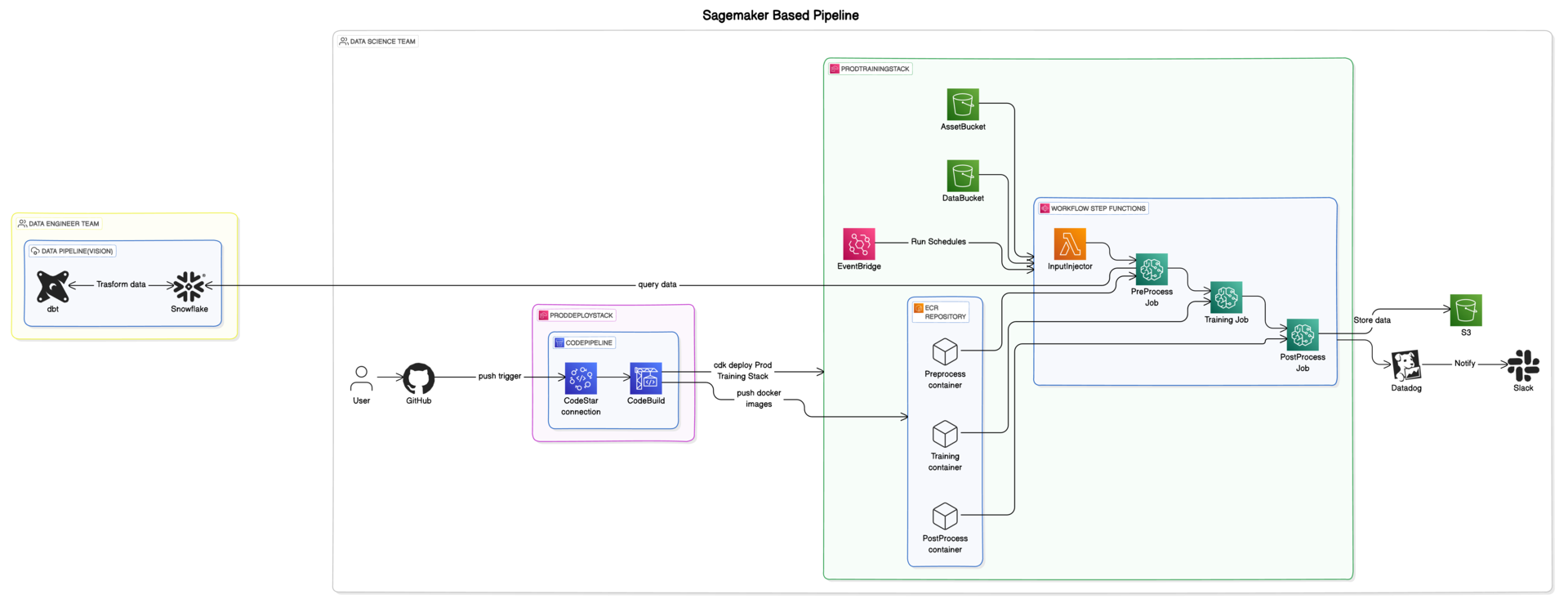
Sagemakerパイプラインの特徴
責務範囲の縮小
- データパイプラインをデータエンジニアに委任し、機械学習パイプラインに専念できるようになりました
- チーム間の役割分担が明確になり、作業効率が向上しました
A/Bテストの容易化
- CDKを用いた一括インフラ管理により、本番環境と同じバッチ構成をブランチから簡単にデプロイできるようになりました
- テスト環境で迅速にA/Bテストを実行することが可能になりました
コンテナ化
- PythonスクリプトをSagemakerでコンテナ化し、環境差異を最小化しました
- 開発環境と本番環境間の互換性が向上し、リリースプロセスがスムーズになりました
開発インスタンスの不要化
- 開発用EC2インスタンスが不要となり、ローカル環境での開発が容易になりました
- 開発コストの削減と迅速なプロトタイピングが可能になりました
Prefectベース基盤への移行(2023年〜現在)
チーム状況
SageMakerのパイプライン導入により、データサイエンティストとデータエンジニアの役割が明確に分離されました。データサイエンティストは機械学習基盤の開発と運用を担当し、データエンジニアはデータ基盤の開発と運用を責務としていました。
この体制下で、データサイエンティストチームには、プロダクトに対してより大きな価値を迅速に提供することが求められました。特に、新しい施策や機能を継続的かつ迅速に試行することが重要な目標となりました。
そこで我々は、チームメンバー個々のスキルレベルに関わらず、誰でも簡単に新しい施策を最短時間で試せる環境の構築を目指しました。
SageMaker / Step Functions環境を使って見えてきた課題
実際にSageMaker基盤を使っていたのは1年半ほどでした。上記の記載されている良い点はたくさんありますが、実際に運用して見えてきた課題もありました。
主に以下に3つです。
- インフラ構築の複雑さ
- ワークフローの柔軟性
- ログ監視
1. インフラ構築の複雑さ
当初、CDKによるインフラ管理は慣れの問題だと考えていましたが、運用を重ねるにつれてその複雑さが明らかになりました。特にA/Bテストのような一時的な実装に対しても高いコストがかかり、データサイエンティストの負担が増大しました。結果として、開発速度の低下やエラーの増加といった問題が顕在化しました。
2. ワークフローの柔軟性
Step Functionsを使用したオーケストレーションでは、タスク間のデータ受け渡しや新規タスクの追加が困難でした。複雑な記法も相まって、システムの拡張性や保守性に課題が生じました。
3. ログ監視
CloudWatch Logsでのリソース別ログ管理は、ログの散在を招き、効率的な監視を困難にしました。Lambda、SageMaker Jobs、Step Functionsなど、複数のサービスにまたがるログの確認が必要でした。
Prefectを選定した理由
ワークフロー管理ツールには多くの選択肢がありますが、私たちが最終的に選んだのはPrefectです。
その理由は、すべてをPythonのエコシステム内で統一して記述できる点にあります。これにより、異なる技術スタックを扱う必要がなく、インフラからバッチ処理に至るまで、全工程をPythonで一貫して記述可能です。
また、既存のPython関数にデコレータを追加するだけで簡単にタスクを定義でき、タスク間のパラメータ設定や複雑なワークフローの構築も直感的に行えます。
さらに、データサイエンティストがフルサイクルで開発を進め、そのコードに完全なオーナーシップを持つことができる点も重要です。
ゆえに、機械学習エンジニアとデータサイエンティストの役割分担が厳密でない私たちのチームにとって、Prefectは最適なツールであると判断しました。
アーキテクチャ図
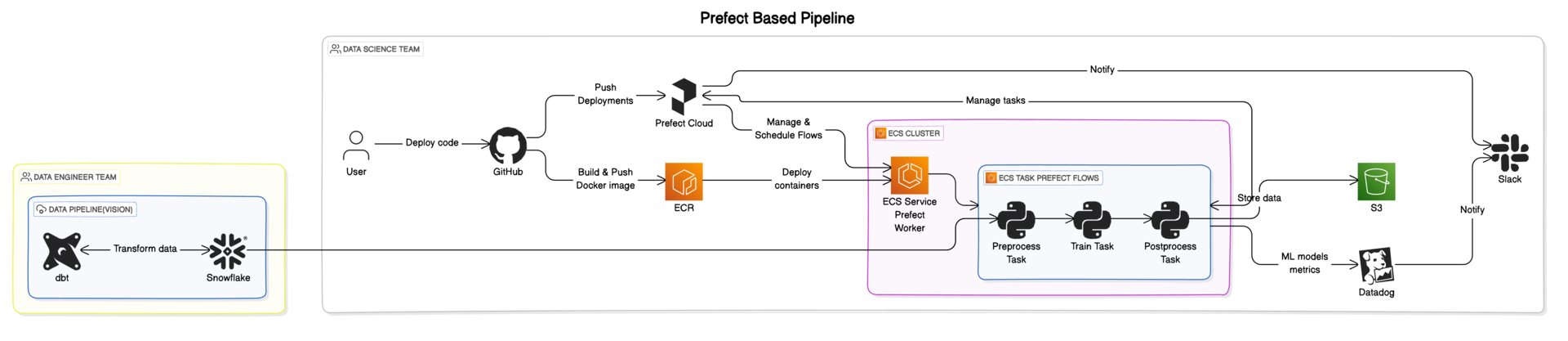
Prefectを使ったパイプラインの特徴
Pythonエコシステムとの完全な統合
- インフラからバッチ処理まで、全てをPythonで一貫して記述できるように
- チームの既存のPythonスキルセットを最大限に活用
直感的なタスク定義
- 既存のPython関数に簡単なデコレータを追加するだけでタスクを定義
- タスク間のパラメータ受け渡しや複雑なワークフローも直感的に記述
スケーラビリティとパフォーマンス
- 大規模なワークロードにも対応できる高いスケーラビリティ
- 効率的なリソース管理により、パフォーマンスが最適化
- 大規模で複雑なデータパイプラインの管理が容易に
モニタリングと可視化
- UIによる詳細なログ記録と可視化機能
- 問題の迅速な特定とデバッグが可能
Prefectを使ってみた感想
現時点での使用感として、Prefect Cloudを利用することで、機械学習パイプラインの運用負荷が大幅に軽減されました。
インフラのコード化(IaC)についても、必要最低限の記述で済むようになりました。
例えば、バッチ処理用のインフラはPrefectのモジュールを利用することで、AWSのECSタスクを簡単に設定できます。設定ファイルを用意するだけで、Pythonからインフラの部分を記述することが可能です。
さらに、Prefectでは一つの管理画面でバッチの状況を一元的に確認できるため、運用監視が非常に容易です。これは、SageMakerのように各プロセスごとにアーキテクチャの状況を別々に監視する必要があった場合と比べ、ログ監視が格段に簡単になりました。
これにより、データサイエンティストはより本質的な課題に集中できるようになりました。
ただし、ユーザー課金モデルであるため、大規模なチームにはコスト面で適さない可能性があります。
まとめ
今回はCARTA MARKETING FIRMの機械学習がLuigiベース基盤、 SageMakerベース基盤、 Prefectベース基盤と変貌を遂げた過程を紹介しました。
以下にデータサイエンスチーム目線でのそれぞれのパイプラインの評価を以下のようにまとめてみました。
| Luigiベース基盤 | Sagemakerベース基盤 | Prefect Cloudベース基盤 | |
|---|---|---|---|
| データサイエンティストの責務範囲の狭さ | ❌ | ⭕ | ⭕ |
| A/Bテストの容易さ | ❌ | ⭕ | ⭕ |
| 開発体験 | ❌ | ⭕ | ⭕ |
| 実装コスト | ⭕ | 🔺 IaCの認知負荷が高い | ⭕ |
| ワークフローの柔軟性 | ⭕ | 🔺 StepFunctionでの記述が困難 | ⭕ |
| ログ監視 | ⭕ | 🔺 リソース別のCloudWatch logsを見る必要がある | ⭕ |
| 費用 | ⭕ | ⭕ | 🔺 ユーザー課金のため |
- データサイエンティストの責務範囲の狭さ
- データサイエンティストがオーナーシップを持つ範囲
- A/Bテストの容易さ
- 施策の効果検証をするまでのリードタイム
- 開発体験
- ローカル環境でワークフローの動作確認ができるか
- 使い始めるのがどれだけ簡単か(APIの仕様)
- 実装コスト
- インフラ周りの複雑さ
- IaCまわりの認知負荷の高さ
- ワークフローの柔軟性
- 新しいタスクの追加やパラメータの追加の容易さ
- ログ監視
- 各種タスクのログ
- 費用
- パイプライン全体のお金に関するコスト
繰り返しになりますが、、我々の目指す理想の機械学習基盤の姿はデータサイエンティストが最も付加価値を生み出す部分に集中し、時間を費やすことができる基盤です。
現状のPrefectベース基盤により、データサイエンティストが施策を迅速に試せる環境が以前より整えることができました。
しかし、まだ理想な機械学習基盤を作れたとは思っていません。課題はまだまだいっぱいあります。 現在、以下のような課題に取り組んでいます:
- 機械学習モデルのバージョン管理の最適化
- より効率的な機械学習モデルのサービング基盤の構築
- 機械学習モデルのE2Eテスト、リグレッションテストの強化
- データ品質管理とモニタリングシステムの改善
- モデルの説明可能性と透明性の向上
機械学習基盤の改善や、データサイエンスの最前線での取り組みにご興味がある方は、ぜひご連絡ください。