



こんにちは、株式会社CARTA MARKETING FIRMのデータエンジニア、@pei0804です。
昨年、私たちはSnowflakeを中心に据えた「Vision」という新データ基盤構想を立ち上げました。 それから1年、多くの変化がありました。この記事では、Snowflake導入によって現場に起きた変化、直面した挑戦、そして見出した可能性について、率直に語ります。
当記事は、話が膨らみすぎるため、データ利用部分については深く触れませんが、別の機会にどういうことを行っているかを紹介したいと思います。
Snowflake導入の経緯と初期の構想
そもそも、Snowflakeを、なんで導入するんだっけ?については、以下のスライドで詳しくまとめていますが、簡潔に説明すると、色んなクラウドにあるデータを簡単に集約できて、かつ、スケーラビリティに問題がなく、枯れた技術をうまく使ってそうで安心感があったからです。
ぼくのかんがえる最高のデータ分析基盤 / strongest-data-architecture-discussion - Speaker Deck
全体から見た変化
図の読み方は、赤枠が変化があった部分で、青枠が変化後の状態を表しています。
2022年11月 運用開始時点
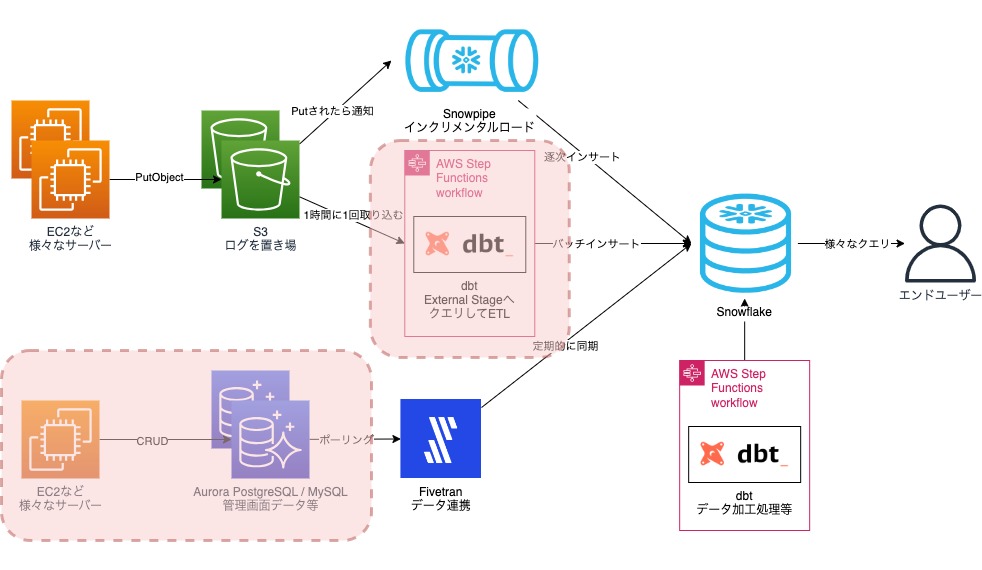
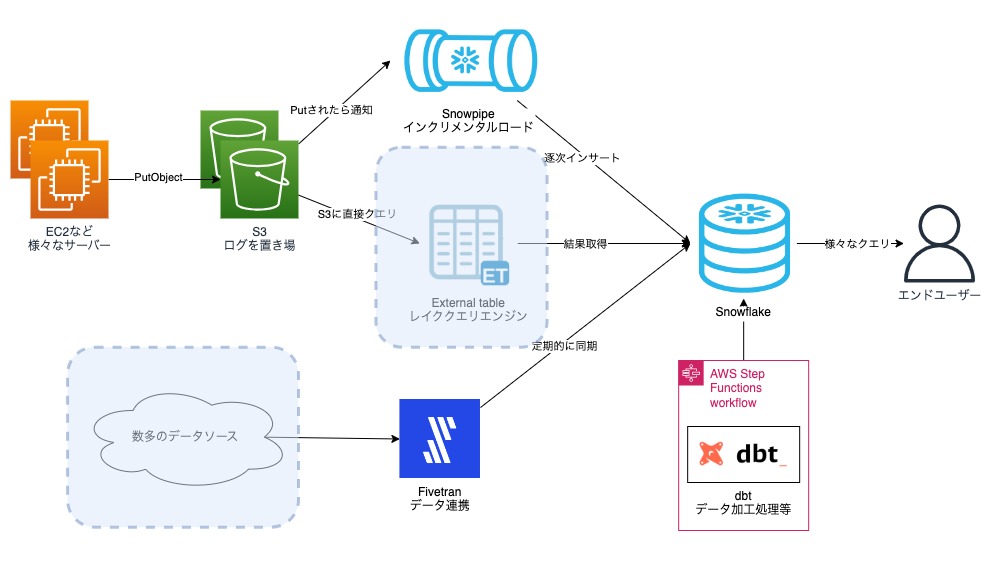
2023年12月 現在
Snowpipeの活用拡大
Before
- データを比較的早い段階で参照する必要な場合のみSnowpipeを使用していました。 それ以外の場合は、External Stageとdbtを組み合わせたバッチロード。
After
- 9割近くのワークロードをSnowpipeでカバー。 元々全面的に採用できなかった理由は、ログファイルの要件とSnowpipeが合っていなかったことが原因でしたが、それらを解消した結果、全面的に採用してもコストパフォーマンスが合うようになりました。
External Tableを活用したアドホックなデータ要件の対応
Before
- 初期は利用していなかった。理由としては、External Tableを使用するには、直接クエリされることをある程度想定したログ設計になってる必要があったため。 初期段階では、使おうとすると、パーティション作成時にオブジェクト数が多すぎることでエラーが発生してしまっていた。
After
- Snowpipeの全面適用の一貫で、ログが扱いやすい形になったことで、External Tableにとっても扱いやすい状態になり、使える状態になりました。 主なユースケースは、アドホックな分析で、常にSnowflakeに永続化するほどでもないけど、たまにクエリしたいやつに、バッチリとハマっています。 他にも、外部から提供されたレポートデータを参照する時に使っているケースもあります。
dbtモデル数が10倍
Before
- Snowflakeにロードされたデータを、変換する。
- External Stageを用いたデータ取り込み。
- モデル数50個
After
- データ取り込みは行わなくなった。データ変換のみ。
- Backfill Botを使ったBackfill業務の一般化。
- Elementary Cloudの導入
- モデル数500個
dbtに関して、役割は大きく変化していません。ですが、モデル数は10倍近くになり、それに伴って開発フローやレイヤリングは、継続的に見直しがされています。 2023年末時点のdbtの全貌については、以下の記事でまとめているので、そちらを御覧ください。
開発体制が中央集権からDataOpsへ
Before
- データ基盤チームが、各プロダクトデータ取り込みから、dbtモデル実装から運用まで行う。
After
- 各プロダクトがデータ取り込みから、dbtモデル実装・運用は、プロダクトチームが管理する。
運用開始直後は、dbtプロジェクトがどのように変化していくのか、どういうニーズがあるのか、また、社内でそこまでdbtが認知されていなかったフェーズだったのもあり、データ基盤チームによる中央集権的な体制で管理をしていました。
しかし、段々と扱っているプロダクトのデータの数が増えてくると、ドメイン知識のキャッチアップにコストがかかり、管理ができているとはいい難い状態になってきました。
例えば、dbt testが落ちたという通知が来た時に、これがどれくらい緊急度の高いものかは、モデルの作成者じゃないと判断つかないなど。それを都度エスカレーションしたり、それっぽい対応入れてみたり、これだといずれ回らなくなると判断し、DataOpsを明示的に導入しました。
DataOps導入には、データオブザーバビリティが必須です。 ツールとしては、Elementary Cloudを利用しています。どのようにDataOpsを実現してるかについては、また別の記事で取り上げたいと思います。
Fivetranの一貫した利用価値と拡張可能性
Fivetranは導入以来、変化することなく、我々のデータエンジニアリング業務にとって重要な役割を果たし続けています。
役割は導入当初から変わらず、Snowflake単体だと、データ連携するのが困難なユースケースに積極的に採用しています。 多くのデータソースに対応してくれているので、今後も活躍場面は広がるだろと考えています。
コストパフォーマンス最適化の効率化
Before
- Snowflakeのコンソール画面。
- SELECT OSSパッケージ
After
- SELECT SaaS版 を使った可視化と最適化
導入初期は、優先度の問題で、コストは度返しで進めていました。特に可視化や最適化に関しては、リソースを割いてる余裕がなかったです。 しかし、皮肉なことに、コスト面で問題が起き始めても、対策を打とうとすると想像以上に手間暇がかかり、継続して行えていませんでした。
現在では、SELECTを導入したことで、短時間で現状把握と対策案まで出せる状態になりました。本当に便利なので、是非チェックしてみてください。
データ利用の変遷と進化
Before
- 特定のプロダクトのためのレポーティング。
After
- 多数のプロダクトに対するレポーティング、分析、機械学習モデルの訓練データ生成
「とりあえず、このデータ基盤を使っとけば、いい感じにデータが入り、変換され、使える」という印象が社内で広まったこともあり、導入が加速したと考えられます。初めから意識していたデータ基盤の扱いやすさが、その普及と使われるデータ基盤への成長において、重要な要素となりました。
やって良かったこと
この1年弱、色々な取り組みをやってきましたが、これはやってよかったなというのを、いくつか紹介したいと思います。
運用
Snowflakeを導入したこと
Snowflakeの導入は重要な一歩でした。導入前はRedshiftとBigQueryを併用していましたが、理想的な状態には至っていませんでした。Snowflakeを選択したことで、私たちの事業が直面するデータ課題を包括的に解決できるようになりました。
導入後は、事業の性質とマッチしていたので、便利なことは想定済みでしたが、予想以上に迅速にデータ活用を進めることができました。これは、Snowflakeの安定性と優れた機能、そしてサポートの賜物です。今後も、Snowflakeを活用してデータからさらなる価値を生み出していきたいと考えています。詳細な導入ストーリーは、以下のスライドでまとめています。
アドテクのビッグデータを制するSnowflakeの力 / data-cloud-world-tour-tokyo-2023 - Speaker Deck
多様性と均質性のバランス
経験上、データロードと変換プロセスにおいて均質性を保つことがデータ基盤の複雑性を低減します。 現実はデータ基盤に適合しない要件が存在します。短期的にはデータを急いで基盤に取り込みたくなりますが、長期的には基盤側を変更するのではなく、コントロール可能な範囲で要件を見直し、基盤のベストプラクティスに適合させることが望ましいです。
データロードには普遍的なベストプラクティスが存在し、これを周知し、新しく生まれるデータを扱いやすい形になる当たり前を作ることは重要です。 また、複雑すぎる要件は、その複雑性に見合った成果を出していないことが多く、本質を見極めて簡素化することが効果的です。 このような変更は手間がかかり困難かもしれませんが、長期的に見るとデータの複雑性を基盤に持ち込まないことが利益につながります。
これらの地道な取り組みもあって、記事の冒頭でも触れましたが、Snowpipeがワークロードの大部分を効率的に処理できるようになりました。これはベストプラクティスの導入と徹底の成果です。現在では、新しいデータの取り込みは誰でもできる状態にまで一般化されました。
一方で、データが最大の価値を発揮する瞬間や利用場面では多様なニーズを受け入れることが重要です。
チームマネジメント
基盤チームとプロダクトチームの責任範囲の明確化
基盤の活用範囲が広がるにつれ、データ基盤チームの責任範囲に関する問題が浮上しました。
初期の導入段階では、データ基盤チームがデータロード、モデリング、レポーティング設計の全工程を担当していました。 しかし、ビジネスの進化と共に新たな要件が生まれ、都度、誰がこれらの要件を担うべきかという問題が生じました。 また、ドメインに詳しくないと実装が難しい要件も増えてきたことで、徐々にプロダクトチームがこれらのタスクを引き受けるようになりました。
ですが、事あるごとに「基盤チームとプロダクトチームどっちがやる?」とコミュニケーションが発生していました。 そこで、責任範囲を明確に定義しました。このアプローチは一定の効果がありました。 データ基盤チームが対応すべき事項とプロダクトチームで完結できる事項が明確にしたことで、結果として良い意味で、コミュニケーションの回数が減少しました。
ただし、この責任分担は時間と共に変化していくものであるため、継続的な見直しが必要であると感じています。 既に責任範囲を定めた時から現在に至るまで、微妙な変化がありました。これからも、状況に応じて責任範囲のアップデートを行うことの重要性を感じています。
実際の責任範囲はこちらです。
# 基盤 データ基盤チームの責任範囲は、データ基盤の保護と安定性を確保するため、バッチやアプリケーションの安定稼働や監視を行います。具体的には、ソフトウェア、ネットワーキングなどのインフラストラクチャの保護、基盤となるサービスの保守やアップデート、セキュリティ対策などを実行します。また、基盤で動作する各バッチやアプリケーションの適切な稼働状況を監視し、障害発生時には迅速な対応を行います。 さらに、利用者からのコードレビューの依頼を受け、必要に応じてコードの改善を行います。基盤に足りない機能が明らかになった場合には、その開発も行います。 また、データを扱う上でのベストプラクティスを定義し、それを利用者に伝え、適用を促すことも責任の一部とします。 タスク例 * 基盤で扱っているライブラリのアップデート * Snowflake、 dbtの新しい機能の基盤への取り込み。 * データカタログの提供。 * コスト可視化 * 監視ツールの提供。 * 全体の権限管理の設計。 * 設計指針の定義。 # 利用者 Visionの利用者は、データの取り込み設定の追加やビジネスロジックの実装(例えば、dbtモデルの作成など)を行います。また、タスクの冪等性を保証し、必要に応じてデータの再取り込み(バックフィル)を行うなどの責任も負います。さらに、データの管理(マスキングや暗号化オプションを含む)、適切なアクセス権限の設定なども利用者の役割となります。 必要に応じて、ライブラリの追加やパッケージの追加なども行い、システムに組み込むことができます。基盤に触れることは逆に推奨しており、より効果的な利用を促しています。 タスク例 * dbt modelの作成。 * 連携先AWSアカウントの追加。 * Snowpipe、 External TableなどのData Ingestionの設定追加。 * ビジネスロジックの誤りを修正するために、コードリバートした上で、バックフィルする。 # 大事なこと データ基盤チームとして、我々はユーザーの責任範囲を明確に定義していますが、絶対厳守なルールではありません。初めてデータ基盤を利用する際のサポートはしっかりと提供し、スムーズなスタートが切れるようにします。 さらに、日常的な疑問やデータに関する相談なども随時受け付けています。上記の責任範囲は我々の基本的なスタンスを示すものであり、具体的な対応は状況により柔軟に変わります。場合によっては、例外的に積極的に手を動かしてサポートすることも想定しています。
新卒採用
2023年4月、私たちのデータ基盤チームは新卒社員を迎え入れました。 当時、チームは私と業務委託の方の2名体制で、大変ながらも順調に進行している段階でした。 しかし、この少人数体制は、長期的に見た時に体制として脆弱なのは明らかでした。そこで、新卒を採用し今からチーム体制強化の仕込みを行うことにしました。 正直、データエンジニアの新卒採用は挑戦的な試みでした。恐らく私だけではなく、新卒社員も不安はあったと思います。
チームに配属してからは、実務と座学をひたすら行ってもらいました。 データパイプラインの設計、ディメンショナルモデリング、Snowflakeのアーキテクチャ、dbtの実装プラクティス、DesignDocの書き方、そして、もちろん実践も。 入社から1年も経たずに、新卒社員は顕著な成果を上げ、データ基盤の強化に大きく貢献しました。
特に大きな変化があったのは、データ基盤のミスが発生しにくい仕組みの強化です。 元々はシニアクラスのエンジニア2名で運営していたチームでしたが、新卒社員の参加により、良い意味で、不十分なシステムやプロセスが明らかにされ、より堅牢でミスの少ないデータ基盤へと進化しました。実際、事故発生する回数が激減して、圧倒的な安定性を保っています。
また、私が腰重くて試せていなかったやりたいことシリーズにも積極的に取り組んでくれました。 SELECTとElementary Cloudの導入は、新卒社員が率先して行ってくれたことで、本番で試せる環境が構築され、導入まで一気に進めることができました。
やはり、関わる人が増えると、面白いことが起きますね。
今後の展望
今後は、データ基盤のさらなる活用範囲の拡大を図ります。
また、せっかく一箇所にデータが集約されているので、複数プロダクト間のデータ利用と統合も模索したいところです。 加えて、チームの拡大と人材育成にも力を入れ、データ駆動型の未来を実現するための基盤を固めていきます。