




概要
こんにちは、4月に新卒で株式会社CARTA HOLDINGSに入社し、現在はCARTA MARKETING FIRMのデータエンジニアをやっているharukiです。
私たちのチームでは、dbtとsnowflakeを使ってデータ基盤を構築しています。
データ基盤を使うエンジニアが増え、dbtのモデル数が増えてきたのですが、その中には使わなくなり削除したdbtモデルもありました。 dbtモデルを削除しても、Snowflake上の対応するテーブルやビューは自動的には消えないため、使われないsnowflake上のテーブルやビューが増えて目立つようになってきました。
そこで、dbtモデルとしては削除されているが、snowflake上に残ってしまっているテーブルやビューを一括削除できる処理を考えました。
想定読者
- dbtとsnowflakeを使ってデータ基盤を開発している方
この記事を読んでわかること
- 使っていないsnowflakeのテーブル、ビューを見つける方法
- それに対して私たちのチームがどういう運用をしているか
開発体制
まず私たちのチームの開発体制を簡単に紹介します。
データ基盤を使うのは二つのチームに分かれています。
- dataチーム
- データ基盤の安定稼働・機能開発を行うのがメイン業務ですが、時にはプロダクト開発チームのサポートも行い、基盤の活用を促します。
- チームトポロジーで言うところのPlatformチームであり、Enablingチームです。
- プロダクト開発チーム
- 自分たちのプロダクトのニーズに合わせたdbtモデル開発をします。
- チームトポロジーで言うところのStream alignedチームです。
そしてdbtをシングルプロジェクトで運用し、プロダクト開発チームはそのプロジェクトをプロダクトごとに区切って利用しています。dataチームはその管理者になっています。
システム構成は以下のようになっています。
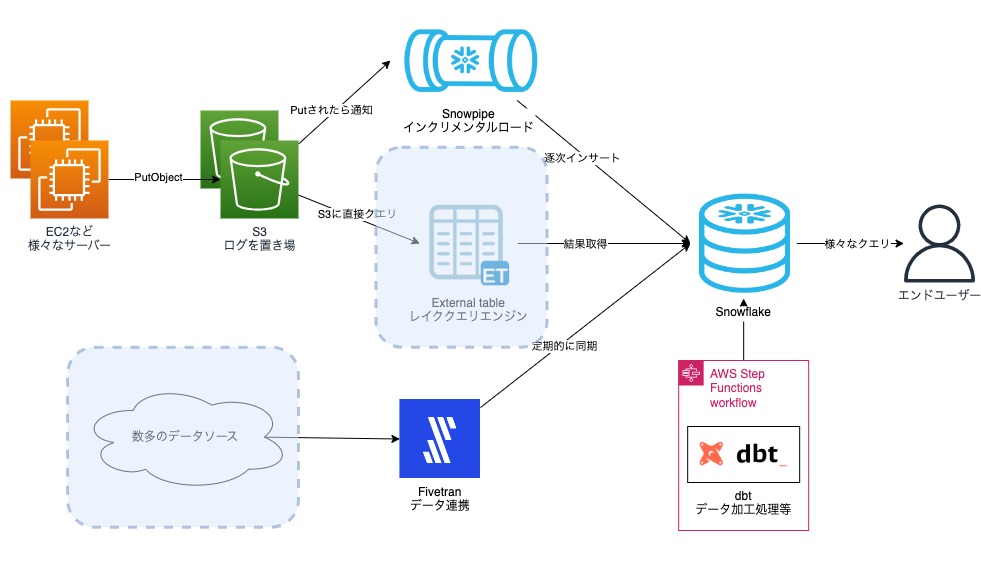
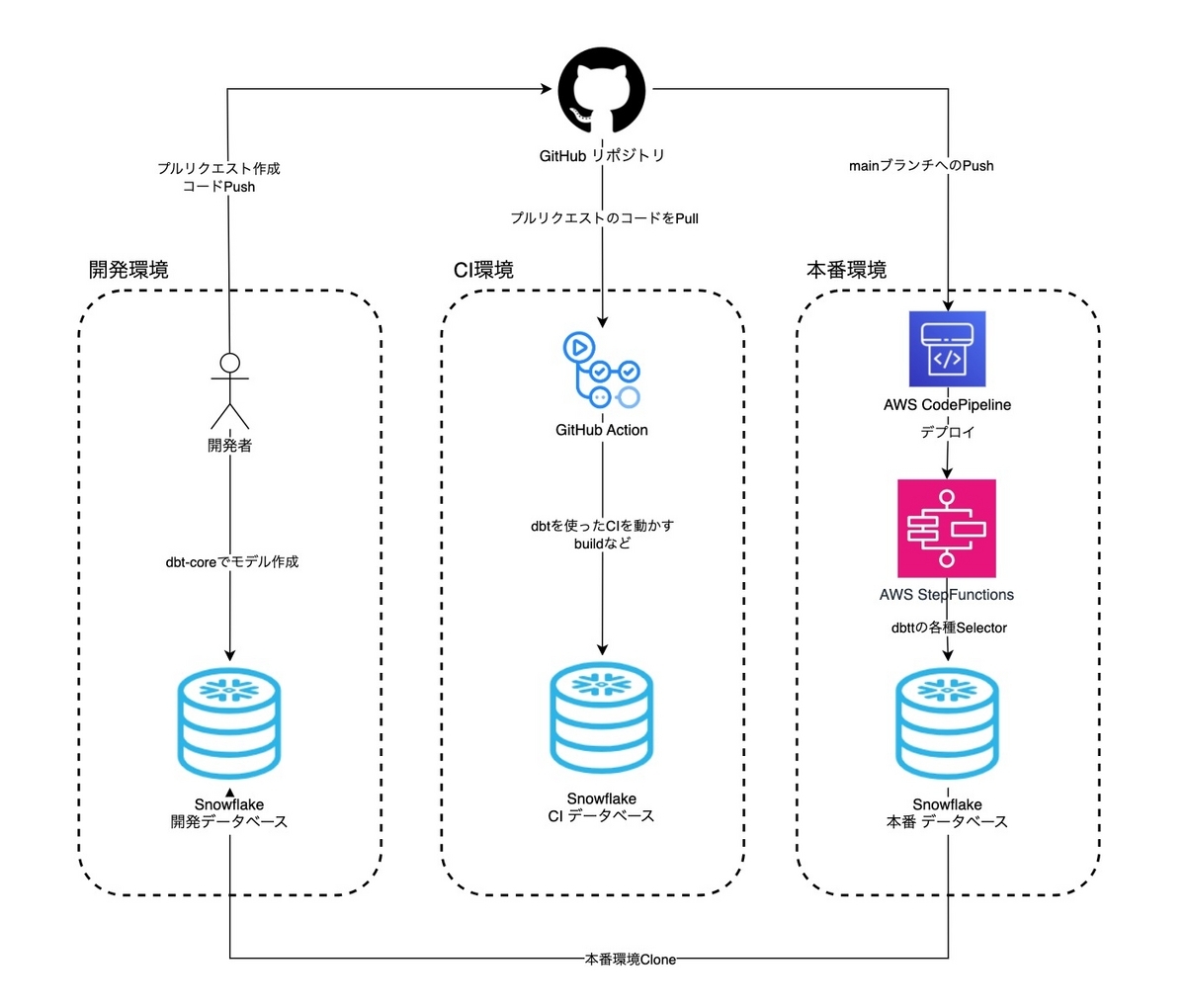
開発環境とCI環境と本番環境は以下のように分けて運用しています。
使っているdbtパッケージ
- elementary
- dbtネイティブなデータオブザーバビリティツールElementaryが提供するパッケージ。
- 内容としては、dbtの振る舞いに関するメタデータ生成をしているパッケージです。弊社では、Elementary Cloudを使っているので、その連携にも利用しています。
- dbt-snowflake-monitoring
- Snowflakeの力を引き出すためのdbtを活用したデータ基盤開発の全貌
- Snowflakeと共に過ごした一年間。その進化過程と未来へのVision
生じた問題
dbtモデルをコード上から削除すると、そのモデルに対してdbt buildが走らなくなり更新が止まります。 更新がなくても使う可能性があるものなら良いのですが、削除しなければ、snowflake上に使わないテーブルやビューは残ったままになってしまいます。
プロダクト開発チームがdbtモデルを削除したらsnowflake上のリソースを消すようにお願いするような運用も考えられます。しかし、容易に消し忘れが生じることが考えられ現実的ではありません。
データ基盤を利用するユーザーが増えてきてこのようなゾンビモデルが目立つようになってきました。
残っているとどうなるのか、立場ごとにリスト化します。
プロダクト開発チーム側
- データ基盤を使う
- クエリしてみたら最新のデータがない。どうなってんの?って話が始まる。
- テーブルにクエリしてみたがデータが取れないので調べて見てほしいという依頼を受けたが、そのテーブルはしばらくの間更新されておらず、新しいモデルに作り変わっていたということがあった。
dataチーム側
- データ基盤を管理する
- 使っていないテーブルは削除してストレージコストを減らしたい。
少人数のチームで管理しているのですが、dbtモデル数が500近くあり、全てを把握するのは難しい状態になっています。さらにその中に使っていないものがあると、その確認作業が必要になります。
snowflakeから見れば、モデルがdbtで管理されて、更新されるものなのかはわかりません。dbtを使っているエンジニアならわかりますが、dbtを使わない人にとっては確認が不可能になります。snowflake上には管理され更新されるテーブル、ビューのみがあるのが理想でその状態を保ちたいというモチベーションがあります。
解決方法
elementaryが作ってくれるdbt_artifactsを利用します。
dbt_artifactsはmanifest.jsonなどの成果物から取れるdbtのメタデータをわかりやすいように加工したものです。elementary packageをdbtのプロジェクトで使っていると、dbtモデルの実行後に作られます。
利用するテーブル
- snowflake tableビュー
- データベース内にあるテーブルのスキーマ名、モデル名、テーブル型などを見ることができます。
- dbt_models
- 各dbtモデルのデータベース名、スキーマ名、モデル名、マテリアライゼーションなどを見ることができます。
- 各dbtモデルのモデル名とsnowflake上に作られるテーブル名が一致することを前提としています。
私たちのチームではRAW、PREP、PRODの3つのデータベースを使ってレイヤーごとに分けて運用しています。
RAWに対してはdbtを使って書き込みをしない方針なので、今回の対象はPREPとPRODデータベースです。
この二つのデータベースのinformation_schema.tablesビューに対してクエリした結果とelementaryが作ってくれるdbt_modelsに対してクエリした結果の差を見ることで使っていないテーブル、ビューをシンプルに取得することができます。
テーブルとビューではデータが物理的に存在するかしないかの違いがあり、テーブルの削除とビューの削除では間違って消してしまった際の復旧の大変さが異なります。(snowflakeにはTimeTravelという便利な機能がありますが、、)
そのため、テーブルとビューで処理を分けてます。
ビューの場合
with prod as ( select table_catalog as database_name, table_schema as schema_name, table_name from PREP.INFORMATION_SCHEMA.TABLES where table_schema != 'INFORMATION_SCHEMA' and table_type = 'VIEW' ), prep as ( select table_catalog as database_name, table_schema as schema_name, table_name from PROD.INFORMATION_SCHEMA.TABLES where table_schema != 'INFORMATION_SCHEMA' and table_type = 'VIEW' ), -- snowflake上に存在するビュー snowflake_views as ( select * from prod union all select * from prep ), -- dbtモデルとして管理されているビュー dbt_models as ( select upper(database_name) as database_name, upper(schema_name) as schema_name, upper(name) as table_name from ELEMENTARY.ELEMENTARY.DBT_MODELS where package_name = 'your package name' and materialization = 'view' ) -- 最後に差分をみる select * from snowflake_views minus select * from dbt_models;
テーブルの場合
with prod as ( select table_catalog as database_name, table_schema as schema_name, table_name from PREP.INFORMATION_SCHEMA.TABLES where table_schema != 'INFORMATION_SCHEMA' and table_type = 'BASE TABLE' ), prep as ( select table_catalog as database_name, table_schema as schema_name, table_name from PROD.INFORMATION_SCHEMA.TABLES where table_schema != 'INFORMATION_SCHEMA' and table_type = 'BASE TABLE' ), -- snowflake上に存在するテーブル snowflake_tables as ( select * from prod union all select * from prep ), dbt_models as ( select upper(database_name) as database_name, upper(schema_name) as schema_name, upper(name) as table_name from ELEMENTARY.ELEMENTARY.DBT_MODELS where package_name = 'your package name' and materialization in ('table', 'incremental') ), dbt_seeds as ( select upper(database_name) as database_name, upper(schema_name) as schema_name, upper(name) as table_name from ELEMENTARY.ELEMENTARY.DBT_SEEDS where package_name = 'your package name' ), -- dbtモデルとして管理されているテーブル dbt_objects as ( select * from dbt_models union all select * from dbt_seeds ) -- 最後に差分をみる select * from snowflake_tables minus select * from dbt_objects;
このクエリを使って不要なテーブルやビューを削除するクエリを発行してくれる処理が以下になります。
テーブルの場合
import argparse import snowflake.connector from datetime import datetime, timezone parser = argparse.ArgumentParser(description="開発用DBを削除するためのツール") parser.add_argument( "--snowflake_user_name", required=True, type=str, help="このツールを実行するsnowflakeのユーザー名", ) parser.add_argument( "--snowflake_account", required=True, type=str, help="このツールを実行するsnowflakeのアカウント", ) if __name__ == "__main__": print(f"run_at:\n{datetime.now(timezone.utc)}") args = parser.parse_args() print(f"args:\n{args}") ctx = snowflake.connector.connect( account=args.snowflake_account, user=args.snowflake_user_name, authenticator="externalbrowser", ) cs = ctx.cursor() query = f""" with prod as ( select table_catalog as database_name, table_schema as schema_name, table_name from PREP.INFORMATION_SCHEMA.TABLES where table_schema != 'INFORMATION_SCHEMA' and table_type = 'BASE TABLE' ), prep as ( select table_catalog as database_name, table_schema as schema_name, table_name from PROD.INFORMATION_SCHEMA.TABLES where table_schema != 'INFORMATION_SCHEMA' and table_type = 'BASE TABLE' ), -- snowflake上に存在するテーブル snowflake_tables as ( select * from prod union all select * from prep ), dbt_models as ( select upper(database_name) as database_name, upper(schema_name) as schema_name, upper(name) as table_name from ELEMENTARY.ELEMENTARY.DBT_MODELS where package_name = 'your package name' and materialization in ('table', 'incremental') ), dbt_seeds as ( select upper(database_name) as database_name, upper(schema_name) as schema_name, upper(name) as table_name from ELEMENTARY.ELEMENTARY.DBT_SEEDS where package_name = 'your package name' ), -- dbtモデルとして管理されているテーブル dbt_objects as ( select * from dbt_models union all select * from dbt_seeds ) -- 最後に差分をみる select * from snowflake_tables minus select * from dbt_objects; """ print("----------------------------------------") print("drop table queries") print("----------------------------------------") print("use role {dbtモデルを実行するロール};") for row in cs.execute(query): database_name = row[0] schema_name = row[1] table_name = row[2] query = f"drop table if exists {database_name}.{schema_name}.{table_name};" print(query) print("----------------------------------------")
ビューの場合
クエリを置き換えて同じように実行すればクエリを発行できます。
実際に実行してみた結果
ビュー 47件、テーブル19件でした。
思っていたよりありました。
(本番DBで実行しているため、開発用DBの結果は含まれていません)
処理を実行すると以下のようなスクリプトが発行されます。
--------------------------------------- drop table queries ---------------------------------------- use role dbt; drop view if exists PREP.TEST_SCHEMA.TEST_VIEW; ----------------------------------------
これらの処理を自動で走らせることも検討しました。
- 現状どんどん増えていくものではないので頻繁に実行する必要がないこと
- 削除処理が知らないところで走っていて、気づかないうちに消えていることを防ぎたい
上記の理由から手動で実行して発行されたクエリを月1で走らせるという運用をしています。
クエリを走らせるのは以下のコストを見る会で行なっています。
コストを見る会について
私たちのチームでは、主にAWS、GCP、Snowflakeの3つのクラウドサービスといくつかのSaaSを利用しています。
各種サービスのコストをチーム全員が把握し、コスト削減に繋げるために月1でチーム全員でコスト確認会を30分程度で行っています。
やっていることとしては、
- 各種クラウドサービスの月のコストの確認
- 利用しているSaaSの月のコストの確認
- クエリコストが高いクエリパターンの確認
- select devを使ってやっています。
- 詳しい話はこの記事で紹介しています。
- snowflakeの使っていないデータの削除
- ストレージコストが増えていく一方なので月一で使わないデータを削除しています。今回の内容と同様に手動で行っています。
- 使っていないsnowflakeのテーブル、ビューの削除
- 今回紹介している内容です
- 開発用データベースの削除
- 基盤ユーザーは本番データベースをcloneして開発環境を作ってそこで作業しています。本番データベースからデータを削除しても、snowflakeではcloneされたテーブルからの参照が残っていると、物理的なストレージからはデータは消えないため、ストレージコストが減らない仕様になっています。そのため毎回データを削除するたびに開発用データベースを削除しています。
補足
より安全に削除するためには
dbt-snowflake-monitoring が作ってくれるquery_base_table_accessを使います。
このモデルはテーブルへのアクセス履歴をクエリしやすいように加工したものです。dbt-snowflake-monitoringのモデルをビルドした際に作られます。
私たちのチームでは他のプロダクト開発チームが作ったdbtモデルとは別でビルドするフローを用意していて1日1回実行されています。
テーブルごとに最後にアクセスされた日時がいつなのかを集計し、一定期間クエリされていないテーブルに絞り込みます。
以下の例では1週間クエリされていないテーブルに絞り込んでいます。
with table_access_summary as ( select full_table_name, max(query_start_time) as last_accessed_at, max_by(user_name, query_start_time) as last_accessed_by from DBT_SNOWFLAKE_MONITORING.DBT_SNOWFLAKE_MONITORING.query_base_table_access group by 1 ), unused_snowflake_tables as ( select full_table_name from table_access_summary where last_accessed_at <= dateadd('day', -7, current_date) ), -- 削除忘れモデル すでに紹介したので省略しています undeleted_snowflake_table as ( select * from snowflake_tables minus select * from dbt_objects )
削除忘れモデルの結果との共通部分を考えることで、削除忘れかつクエリされていないモデルを取得することができます。
select database_name || '.' || schema_name || '.' || table_name as full_table_name from undeleted_snowflake_tables intersect select * from unused_snowflake_tables;
以下の記事を参考にしました
もしも使っているテーブルやビューだったら
undropしてください
https://docs.snowflake.com/ja/sql-reference/sql/undrop-table
おまけ
elementaryがつくるdbt_artifactはめっちゃ便利です。
私たちのチームはデータの品質管理を目的にelementaryを導入していますが、
データの品質管理を目的としていなくても、dbt_artifactを使ってメタデータへのクエリがしやすくなるのでぜひ使ってみてください。