



当記事は、dbtのカレンダー | Advent Calendar 2023 - Qiita の23日目の記事です。

こんにちは、株式会社CARTA MARKETING FIRMのデータエンジニア、@pei0804です。データエンジニアリングのほか、組織運営やデータエンジニア育成にも携わっています。
本記事では、Snowflakeを中心とした当社のデータ基盤「Vision」と、その中核であるdbtの利用について深掘りします。dbtを活用することで、SQLのみでデータパイプラインを効率的に構築し、作業の効率化を図っています。
dbt導入の詳しい導入背景は以下のスライドでご覧いただけます:広告レポーティング基盤に、dbtを導入したら別物になった話 / tokyo-dbt-meetup-4 - Speaker Deck。
私たちのチームでは、ビジネスに直接価値を提供しているdbtモデルの開発はプロダクトチームのエンジニアによって担当されています。 これは彼らの主業務ではなく、幅広いプロダクト開発の一環です。そのため、dbtやSnowflakeの専門知識を持つ人だけでなく、様々なスキルレベルを持つ人々がアドホックに開発に関わっています。この多様なスキルセットを持つチームに対応するためには、どのような基盤が必要で、どのように構築し、運用しているのか、そして直面した課題とその解決策に焦点を当てています。
具体的には、以下のトピックについて取り上げます
- 開発環境の構成
- CIの範囲と実装
- 本番環境の運用
- 環境間の差分管理
- ドキュメンテーション
登壇や懇親会では語りきれない細かすぎるデータ基盤の話を盛り込んでますので、ぜひご一読ください。 別途Snowflakeにフォーカスした記事を書いておりますので、興味あれば御覧ください。
全体の概要
CI/CDパイプライン
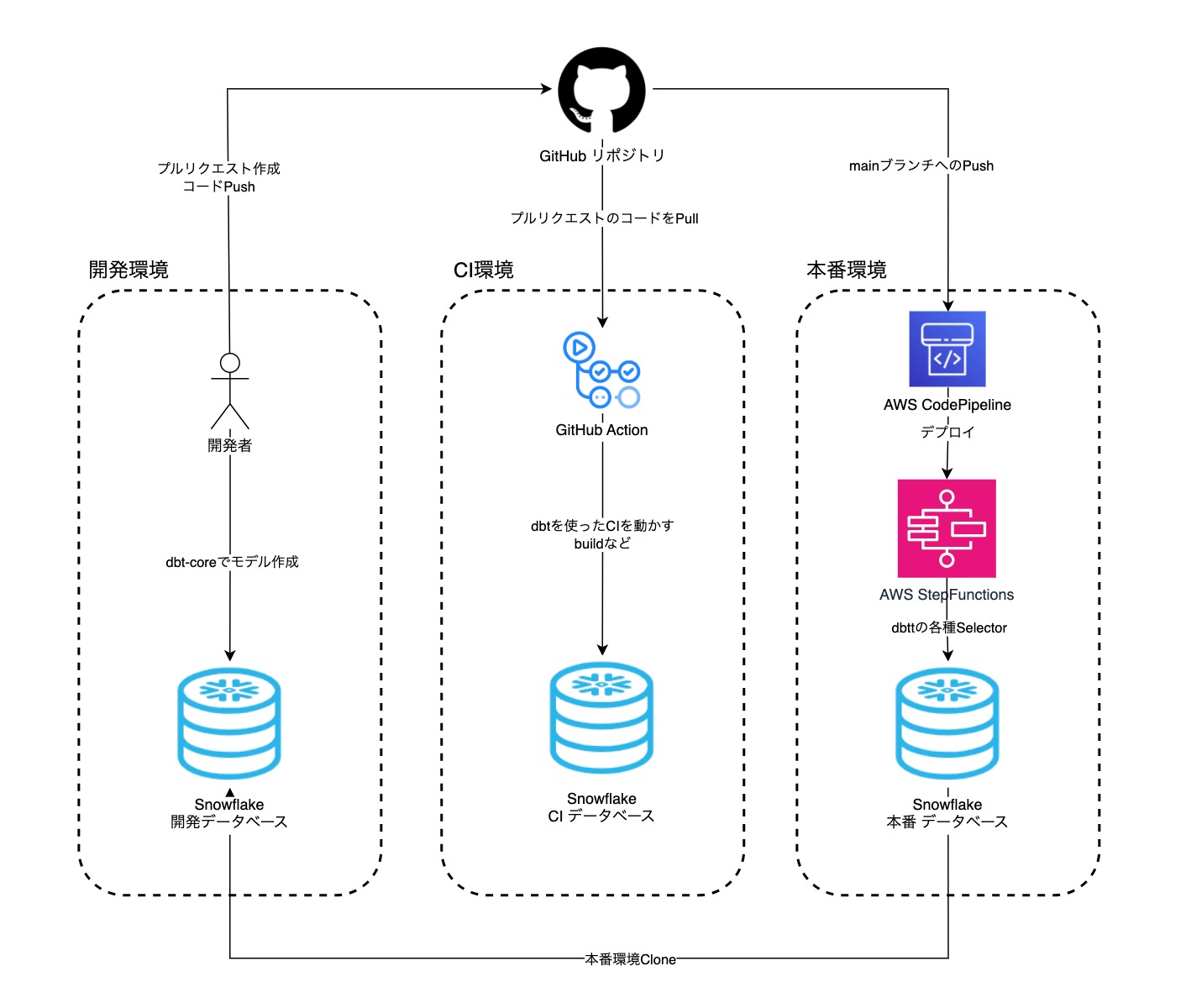
主に3つの環境で機能しています。
開発、CI(Continuous Integration)、そして本番。これらの環境は、同一のコードベースを共有しながらも、それぞれ特有の役割と振る舞いを持っています。dbtマクロを用いることで、これらの環境間の差異を効果的に管理し、各環境での要求に対応しています。
環境差分を埋めるマクロについては、後の章で取り上げます。
シングルプロジェクトアプローチ
dbtプロジェクトはシングルプロジェクト方式で運営されており、複数のプロダクトにまたがるデータを一元管理しています。
異なるライフサイクルを持つデータも、一元管理された形式で扱うことで、管理の複雑さを軽減しています。これにより、基盤チームは効率的な運用が可能です。
また、モデル開発者にとっても、メリットがあります。後述する開発体制で紹介しますが、弊社ではDataOpsを採用しているので、それぞれのデータを、それぞれのデータオーナーが管理しています。
それぞれのドメインに集中して開発できることを重視しつつも、近くに似たドメインの問題を解決してるモデルがあることで、集合知でも戦える体制を築いています。
新たに登場したdbt Meshのようなツールによってマルチプロジェクトアプローチが可能になりましたが、当社では過去の経験からモノリシックなアプローチを選択しています。これは、一箇所での管理のシンプルさと、運用コストの低さから、現時点では最適な選択だと考えています。
利用しているdbtパッケージ
- dbt-labs/dbt_utils
- 多様な汎用的なマクロを提供。データ変換や集計作業を簡素化するために使用している。
- dbt-labs/codegen
- SQLやモデルのコードを自動生成するマクロ。コーディングの効率化をしてくれる。
-
- dbtネイティブなデータオブザーバビリティツールElementaryが提供するパッケージ。
- 内容としては、dbtの振る舞いに関するメタデータ生成をしているパッケージです。弊社では、Elementary Cloudを使っているので、その連携にも利用している。
dbt-labs/dbt_project_evaluator
- dbtプロジェクトのベストプラクティスを確実に遵守するためのツール。プロジェクトの品質向上に役立つ。
- yu-iskw/dbt_unittest
- マクロのユニットテストを容易にするパッケージ。信頼性の高いマクロ開発を支援。
- get-select/dbt_snowflake_monitoring
- SELECT が提供するSnowflakeのコストを可視化するために必要なモデルを構築してくれるパッケージ。
開発環境
開発体制
データ基盤開発・活用推進には、3名のデータエンジニアが専念しています。
データ基盤チームは、チームトポロジーでいうところのプラットフォームチーム兼イネイブリングチームとして機能しています。
基盤の安定稼働・機能開発を行うのがメイン業務ですが、時にはストリームアラインドチーム(プロダクトチーム)のデータに関する技術的サポートと知識の提供にも努めています。 プロダクトチームは、自分たちのニーズに合わせたdbtモデル開発を担当し、より具体的なサービスや機能に集中しています。リリースしたdbtモデルを、それぞれのチームに運用してもらっています。このような開発スタイルは、一般的には、DataOpsと呼ばれているもので、弊社では明示的に導入をしています。
本番同様の開発データベース
各開発者が本番データベースをクローンし、開発者専用のデータベースを構築しています。これはdbt cloneコマンドを用いて実装されています。
この方式により、開発中の変更が他の開発者や本番環境に不意に影響を及ぼすリスクがなくなり、開発のためにダミーデータを用意する必要がなく、最小限の工数で、本番同様の環境下で開発ができます。
Visual Studio Code (VS Code)のプラグイン
dbt開発では、VS Codeの利用を推奨しています。その理由は、dbtと密接に連携する豊富なプラグインが利用可能であるためです。弊社では以下のプラグインを使っています。
- dbt
- Snowflake
- 地味便利
- YAML - Visual Studio Marketplace
- dbtスキーマ読み込ませて使ってます。
- Code Spell Checker - Visual Studio Marketplace
- カラム、モデル名のtypoを防ぐ。
- Copy file name - Visual Studio Marketplace
- モデル名のコピペに地味便利です。
- YAML - Visual Studio Marketplace
CI環境
開発者がdbtモデルを作成する際、GitHubでプルリクエストを作成します。これをトリガーとして、自動化されたCIプロセスが開始され、コードの品質と実行可能性を検証します。
CIの役割は、dbtを熟知していなくても、CIのガイドラインに沿ってコーディングするだけで高い品質が担保されるようにすることです。これにより、基盤チームの詳細なレビューにかかる時間と労力を削減し、効率的な開発プロセスを実現しています。
ちなみに、レビュープロセスは、プロダクトチーム内で回すことが基本で、エッジケースに当たった時に相談を受けるという状態です。基盤チームとプロダクトチームは、物理的にも独立した存在ですが、業務フロー的にも、独立して価値を出すことに集中しています。
コード品質チェック
マクロ名とファイル名が一致するか
マクロの追加は基本的に自由なのですが、マクロ名とファイル名が1:1になるようにしています。
例えば、filter_partition というマクロを作ったら、filter_partition.sql というファイルを作ることを強制しています。 これはファイル名検索でマクロが発見できたり、エディタで見た時に、どういうマクロがあるか一覧しやすいなどの理由で強制しているルールです。
命名規則のチェックに関しては、Pythonでスクリプトを組んで、GitHubActionでチェックしています。
import logging from typing import List from glob import glob check_skip_files = () def check_macro_name_to_file_name(files: List): for filename in files: with open(filename, "r") as stream: contents = stream.read() realfilename = filename.split("/")[-1].split(".sql")[0].strip() logging.info(f"Processing {realfilename}.") if realfilename in check_skip_files: logging.info(f"Skipping {filename} 👀") continue if has_materialization(contents): isolating_materialization = contents.split("materialization ")[1].split(",")[0].strip() if realfilename == isolating_materialization in contents: logging.info(f"{filename} passes! 🎉") continue raise ValueError("Materialization naming error in " + filename) if has_macros(contents): isolating_macro = contents.split("macro ")[1].split("(")[0].strip() if realfilename == isolating_macro in contents: logging.info(f"{filename} passes! 🎉") continue raise ValueError("Macro naming error in " + filename) if has_tests(contents): isolating_test = contents.split("test ")[1].split("(")[0].strip() if realfilename == isolating_test in contents: logging.info(f"{filename} passes! 🎉") continue raise ValueError("Test naming error in " + filename) raise ValueError("Has no macro/materialization/test in " + filename) def has_macros(contents): return len(contents.split("macro ")) > 1 def has_materialization(contents): return len(contents.split("materialization ")) > 1 def has_tests(contents): return len(contents.split("test ")) > 1 if __name__ == "__main__": logging.basicConfig(level=20) files = glob("macros/**/*.sql", recursive=True) check_macro_name_to_file_name(files) logging.info("全てのマクロが、ファイル名と一致しています 🥂")
モデル名に対応するyamlドキュメントが存在するか
dbtモデルを作成する際、そのドキュメンテーションはyamlで記述されます。
当初は、複数のモデルのドキュメントを、フォルダごとに一つのmodels.ymlで管理していましたが、これは可読性とコンフリクトの観点から問題がありました。
そこで、各モデルに個別のyamlドキュメントを割り当てる方法に切り替えました。例えば、hoge_report.sqlモデルに対しては、対応するhoge_report.ymlドキュメントを作成します。この方法は、エディタ等で見た時に、モデルに対応するドキュメントの探しやすさ、ファイル名検索での見つけやすさ、コンフリクトを避けるのにも効果的でした。
このルールを強制するために、Pythonスクリプトでチェックをしています。
import os import glob import logging def check_doc_exists(model_files, ignore_folders): missing_yml = [] for model_file in model_files: if any(ignore_folder in model_file for ignore_folder in ignore_folders): continue yml_file = os.path.splitext(model_file)[0] + '.yml' if not os.path.exists(yml_file): missing_yml.append(yml_file) if missing_yml: logging.error('モデルファイルに対応するymlファイルがありません。') for file in missing_yml: print(f"touch {file}") raise SystemExit('上記のコマンドでymlファイルを作成し、ドキュメントを作成してください。') if __name__ == "__main__": logging.basicConfig(level=20) model_files = glob.glob("models/**/*.sql", recursive=True) # ここにチェックを無視するフォルダをリスト形式で指定します ignore_folders = [ "models/dbt_snowflake_monitoring", ] logging.info("チェック対象外: " + str(ignore_folders)) check_doc_exists(model_files, ignore_folders) logging.info("ドキュメントが全て揃っています🥂")
dbtがベストプラクティスに沿った実装になっているか
github.com/dbt-labs/dbt-project-evaluator を使って、dbtの実装がベストプラクティスに則っているかをチェックしています。このライブラリは非常に便利で、dbtで複数人開発をしている方は絶対に入れた方がいいレベルです。
どういったことをチェックできるか抜粋して紹介します。
- 特定のフォルダ以下のモデル名に、決まったprefixがついているか?
- sourceモデルと直接Joinしてないか?
設定を書き換えることで、それぞれのプロジェクトのプラクティスにカスタマイズも可能です。しかし、後から入れるとほとんどの場合は違反だらけで直すのが大変になるので、プロダクト当初からの導入や早めの導入がおすすめです。
SQLフォーマットチェック
弊社では、SQLのコーディングスタイルを、sqlfmtを使って統一しています。
当初は、sqlfluffも導入していた時期があったのですが、sqlfluff lintが通らないことに関するコミュニケーションコストが非常に高くつきました。有無も言わせず、書き方を強制するsqlfmtの方が一定の品質を担保しつつ、ストレスなく開発ができました。
さらに、sqlfmtの実行速度が非常に速いことも、切り替える大きな理由の一つでした。sqlfluffに比べて、その速さはストレスを微塵も感じさせないレベルです。
但し、sqlfmtとSnowflakeの組み合わせで起きる問題が、いくつかあるので、導入時に気をつけたい点があります。
⚠半構造化データ走査のドット表記
Snowflakeで半構造化データ走査には、ドット表記とかっこ表記があります。
CMFでは、かっこ表記を採用しています。
sqlfluffを使っていた時はドット表記を利用しており、raw_data:requestTime::timestamp_tz の様に走査をしていました。
しかし、このSQLに対して、sqlfmtをかけると、raw_data:requesttime::timestamp_tz の様に全てが小文字に変換されてしまいます。つまり、全く違う意味になるので、SQLが意図しない状態になります。
これについては以下のissueでも議論されていますが、現状も同じ仕様のままなので、注意が必要です。私はこれでデータが壊れry
https://github.com/tconbeer/sqlfmt/issues/269
これに対して弊社では、ドット表記が、そもそも型変換の :: と見分けがつきにくいということもあり、かっこ表記に統一することで、この問題は再発していません。
⚠メタデータカラム
ステージングされたファイルのメタデータ へのアクセスは、metadata$filename の様なカラムを指定します。これをsqlfmtかけると、metadata $filename の様に、スペースが作られてしまいます。これもまた意味が変わってしまいます。
これに対する対応は、Disabling sqlfmt を使うことで対処できます。
-- fmt: off metadata$filename::varchar as _metadata_filename, metadata$file_row_number::bigint as _metadata_file_row_number, -- fmt: on
yamlフォーマットチェック
dbtを開発してると、yamlをそれなりに書くことになるのですが、これも色んな書き方が発生しがちで、収集つかなくなるので、フォーマットするのがおすすめです。
warningチェック
dbt --warn-error ls を流すことで、dbtの実装でwarning判定されているコードがあるかを検知しています。経験的に、dbtのwarningは出てる状態を放置しててもメリットがないので、基本的に許さないスタイルでやった方が時間の節約になります。
実行可能性の検証
新しく追加されたモデルのbuild
追加されたdbtモデルを stateを使って検知して、buildします。
この時に、実データを使って実行していますが、全量のデータは使わないようにしています。 理由としては、全量データでテストすると処理が終わらなくなるからです。
そのかわりに少量のテストを流して、最低限の挙動チェックを行うようしています。以下のようなマクロを組んでいます。 dbtのtargetがciの時に、limitをかけるマクロ。
{%- macro limit_ci(rows_limit=10) -%}
{%- if target.name == 'ci' %} limit {{ rows_limit }} {%- endif -%}
{%- endmacro -%}
時系列系のデータで、limitをかけるマクロ。 最近のパーティションで絞り込んで、limitすることで、最近のデータで試すことを実現する。 データパーティショニング について気になる方は、別途記事を書いてるので、そちらを御覧ください。
{%- macro filter_partition_and_limit_ci(rows_limit=10) -%}
{%- if target.name == 'ci' %} {{ filter_partition() }} {{ limit_ci(rows_limit) }} {%- else -%} 1=1 {%- endif -%}
{%- endmacro -%}
実行時に使うSnowflakeデータベースは、CI用のものでスキーマは動的にコミット単位で作っています。
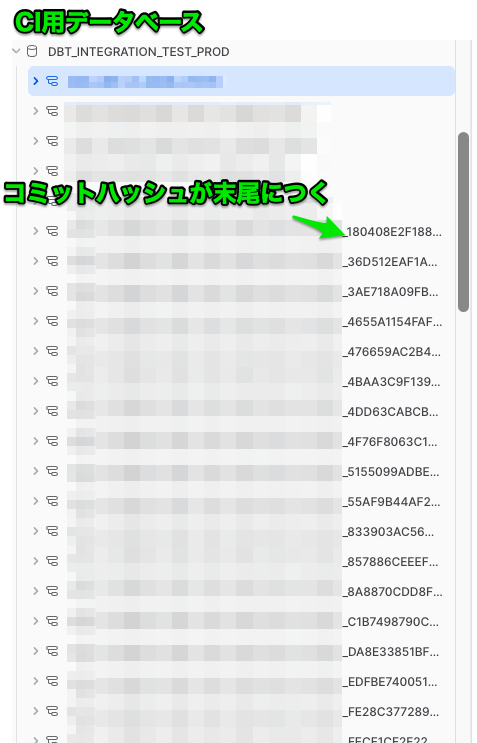
プルリクエストにプッシュしたコミットごとに作られるので、結構な数が生成されます。そして、実はスキーマには上限数があるので、放置しているとエラーになります。そのため、タスクとストアドプロシージャで定期的に消すようにしています。
dbt macroのユニットテスト
github.com/yu-iskw/dbt-unittest
dbt-unittestという便利なライブラリがあるので、こちらを使ってマクロをユニットテストできるようにしています。全てのマクロにテスト追加させるようなルールはなく、適宜追加するスタイルでやっています。仮にテストしないと不安になるような場合、マクロが複雑すぎる可能性があるのでシンプルな方向に落とすように促しています。
An introduction to unit testing your dbt Packages | dbt Developer Blog
シンギュラーデータテスト
Add data tests to your DAG | dbt Developer Hub
dbt modelに対するtestとは別で、データを使ったテストをしています。
いくつかの例を紹介すると、少し込み入ったロジックのマクロを、実際にSnowflake上で、実行した結果をテストしたいケースに使っています。
弊社特有のものだと、dbt projectの設定をテストをするのにも使っています。弊社では、dbtのレイヤリングをSnowflakeスキーマに反映しています。例えば、warehouseレイヤーなら、Snowflakeのwarehouseスキーマで作られるイメージです。
warehouse: +schema: warehouse
仮に+schemaが設定漏れしていると、profileのdefault schemaにモデルが作られます。これは意図してない設定なので、CIで検知して修正を促しています。
手法としては、elementaryのdbt artifactを使ったスキーマが設定されてないモデルを抽出して、default schemaのままのモデルがあったらテストを落としています。
select * from {{ ref("elementary", "dbt_models") }} where schema_name = lower('{{ target.schema }}')
非常に便利なモデルなので、結構重宝しています。 なお、elementaryのartifactsを利用するためには、elementaryのモデルをビルドする必要があります。CIプロセスにこれらのモデルを組み込む場合、事前にモデルのビルドを行うことが必須となります。
dbt実行制御タグチェック
dbtモデルの実行制御にタグを使っています。
build__every_20_minutes- このタグは20分ごとの実行に用いられ、主にディメンションの更新など、アプリケーション設定の迅速な反映が必要な場合に使用されます。
build__every_hour- 1時間ごとの実行に用いられるこのタグは、ビジネスの核となるモデルに属しており、レポーティング、分析、機械学習モデルの訓練データ生成などに使用されます。
build__every_day- 1日に1回実行されるモデルにこのタグが付与され、主に分析用のモデルに利用されます。ここでは、データ確認までの若干のタイムラグが許容されるケースが多いです。
これはTIPSなのですが、tagは一定の命名規則がある方が検索性も上がりますし、コンフィグバリデーションなども仕込みやすいです。
ですが、正しくタグがついてるか、外れたかの判断が、パッと見ではわかりにくいという問題があります。そこで、diffコマンドを使って、変更をわかりやすく確認できる仕組みを用意しています。
CIが実際に変更を検知した時のコメント例。
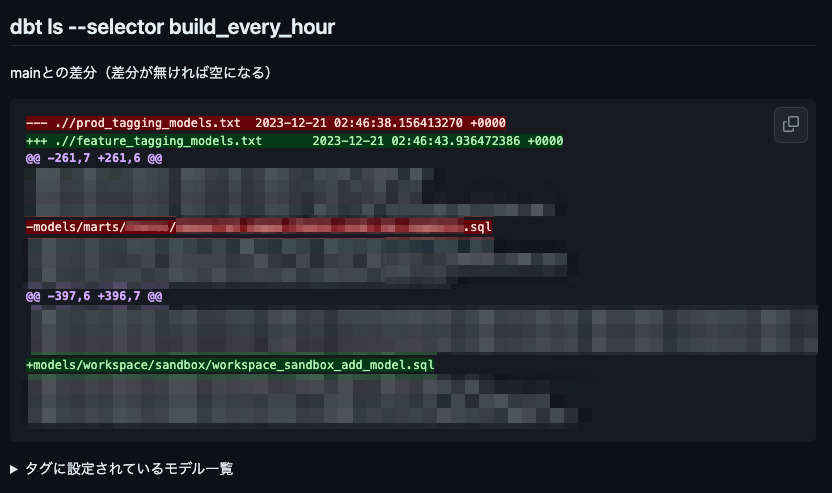
弊社では、500個以上のモデルを管理していて、その半数以上が1時間ごとに動作するincrementalモデルです。間違った設定による事業へのインパクトが大きいため、機械的に変更を検知して、チェックできる仕組みを用意することは重要でした。
同時実行の制御
これらのCIの一部は、Snowflakeでウェアハウスを使って実際に実行されるため、クレジットを消費します。当然、実行したとしても無駄になる可能性があれば、CIの実行を止めたいわけです。
例えば、短時間に複数回コミットとプッシュされた場合、最初のコミットは無駄な実行になる可能性が高いです。
そこで使っているのが、GitHubActionのconcurrencyを使った制御です。簡単にプルリクエストごとの実行重複を制限できるので便利です。
https://docs.github.com/en/actions/using-jobs/using-concurrency
concurrency: group: ${{ github.workflow }}-${{ github.head_ref || github.run_id }} cancel-in-progress: true
本番環境
CD(Continuous Delivery)
mainブランチへのpushをトリガーにCDプロセスを実行しています。このプロセスではAWS CDK PipelinesとGitHub Actionsを使用した自動化されたデプロイメントを実現しています。
CDプロセスにより、以下のタスクが自動的に行われます。
- elementary modelの更新。
- mainブランチのモデルからstateを生成し、S3にPutObjectとして保存。
- CIで使用される差分テストや、開発環境構築用のdbt cloneに利用される。
- StepFunctionsやECSなどのデータパイプライン関連リソースのデプロイ。
オーケストレーション
本番環境では、AWS Step FunctionsとAmazon ECSを使って、dbt-coreを稼働させています。 dbtで表現されるDAGをStep Functionsに完全に反映させるのは技術的に難しいため、現在はこの部分については簡素化しています。
定期的に他のオーケストレーションツールへの切り替えも検討していますが、現状ではStep Functionsの低コストが魅力的であり、変更の必要性が勝るケースに遭遇していません。
dbt-coreを動かしてるAWS Step Functionsの具体的なコスト。

Backfill Bot
データ基盤の運用においては、Backfill(再集計)作業が頻繁に発生します。 これに対応するため、Backfillを容易に実行できるSlackBotを導入しています。このツールにより、修正が必要なdbtモデルの再計算や、新たにリリースされたモデルの過去データに対する再集計が簡単に実施できます。また、スマートフォンがあればどこからでも操作可能なため、問題が生じた場合の迅速な対応が可能です。
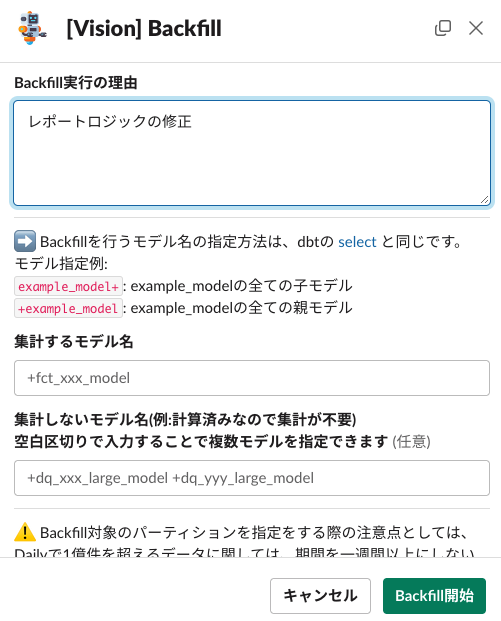
入力項目は以下の通りです。
- Backfill実行の理由
- 理由がわからないと、実行内容の妥当性わからないのと、これがログになるので、地味に大事です。
- 集計するモデル名
- selectで指定するのと同じ。
- 集計しないモデル名 (任意)
- excludeで指定するのと同じ。
- 開始日
- 集計開始日を選択する。
- 開始時間
- 集計開始時間を選択する。
- 終了日(任意)
- 集計終了日を選択する。
- 設定されていない場合は、デフォルトの最大値(9999-12-31)が適用されます。
- 終了時間(任意)
- 集計終了時間を選択する。
- 設定されていない場合は、最大値(23時)が適用されます。
このBackfill Botは非常に便利ですが、便利が故に誤った使用が起きる潜在的なリスク(例えば、過去のレポートデータの改変)もあるため、セーフティ機能の強化に向けた取り組みを検討中です。
環境差分を管理するマクロ
ここまで、3つの環境を紹介してきました。
再掲:CI/CDパイプライン
それぞれの環境でのデータベースやスキーマの扱い方には微妙な違いがあります。これらの差分は、dbtのマクロを使用して効果的に管理しています。
データベース、スキーマ切り替え
dbtのカスタムデータベースとスキーマ機能を利用して、環境に応じてデータベースやスキーマを動的に切り替えます(参照:Custom databases | dbt Developer Hub、Custom schemas | dbt Developer Hub)。これにより、各環境のデータ分離と整合性を確保しつつ、効率的な運用が可能となります。
{% macro generate_database_name(custom_database_name, node) -%}
{%- set production_targets = production_targets() -%}
{#
定義:
- custom_database_name: dbt_project.ymlまたはmodel configで設定されたdatabase name。
- target.name: target名 (devはローカル開発用、 prodは本番用など)
- target.database: profiles.ymlに設定されているdatabase名
前提条件:
- dbtを使った開発をする人は、USERNAME_PROD, USERNAME_PREPが既に作成されていることを前提としています
このマクロの挙動のサンプルは以下の通りです。
(custom_database_name, target.name, target.database) = <output>
(prod, prod, prep) = prod
(prod, ci, prep) = prod
(prod, dev, pei) = pei_prod
(prep, prod, prep) = prep
(prep, ci, prep) = prep
(prep, dev, pei) = pei_prep
#}
{%- if target.name in production_targets -%}
{%- if custom_database_name is none -%}
{{ target.database | trim }}
{%- else -%}
{{ custom_database_name | trim }}
{%- endif -%}
{%- else -%}
{%- if custom_database_name is none -%}
{# ここに通ることは、通常ありえない #}
{{ target.database | trim }}
{%- else -%}
{{ target.database }}_{{ custom_database_name | trim }}
{%- endif -%}
{%- endif -%}
{%- endmacro %}
{% macro generate_schema_name(custom_schema_name, node) -%}
{#
定義:
- custom_schema_name: dbt_project.ymlまたはmodel configで設定されたdatabase name。
- target.name: target名 (devはローカル開発用、 prodは本番用など)
- target.schema: profiles.ymlに設定されているschema名
このマクロの挙動のサンプルは以下の通りです。
(custom_schema_name, target.name, target.schema) = <output>
(hoge_logs, prod, public) = hoge_logs
(hoge_logs, ci, public) = hoge_logs_public
(hoge_logs, dev, public) = hoge_logs
#}
{%- if target.name == "ci" -%}
{%- if custom_schema_name is none -%}
{{ target.schema.lower() | trim }}
{%- else -%}
{{ custom_schema_name.lower() | trim }}_{{ target.schema.lower() | trim }}
{%- endif -%}
{%- else -%}
{%- if custom_schema_name is none -%}
{{ target.schema.lower() | trim }}
{%- else -%}
{{ custom_schema_name.lower() | trim }}
{%- endif -%}
{%- endif -%}
{%- endmacro %}
ウェアハウス切り替え
dbtマクロを使用して、必要に応じて異なるウェアハウス間での切り替えを行います。これにより、リソースの最適化とコスト管理を行いながら、各環境でのデータ処理を行います。
dbt Snowflakeでウェアハウスをモデルごとに切り替える で使い方について解説しているので、興味のある方はこちらを御覧ください。
{% macro get_warehouse(size) %}
{% set available_sizes = ["XS", "S", "M", "L", "XL"] %}
{% if size not in available_sizes %}
{{
exceptions.raise_compiler_error(
"Warehouse size not one of " ~ valid_warehouse_sizes
)
}}
{% endif %}
{% if target.name in ("prod") %}
{# backfill時は、モデルに設定されたウェアハウスサイズだと処理しきれないため、強めのウェアハウスを設定する #}
{%- if var("is_transform_backfill") -%} {% do return("DBT_XL_WH") %}
{% else %} {% do return("DBT_" ~ size + "_WH") %}
{% endif %}
{% elif target.name in ("ci") %} {% do return("DEV_XS_WH") %}
{% elif target.name == "dev_d" %}
{# ローカルでの動作チェック用 #}
{% do return("DEV_" ~ size + "_WH") %}
{% else %} {% do return(None) %}
{% endif %}
{% endmacro %}
環境ごとのprofile
紹介したマクロでは、実行環境に応じて振る舞いを変える判断軸に、target variableを使っています。これは、profileに設定されてる値を、変数として扱うことができ非常に便利です。弊社では、以下のようなprofileを使っているので、参考までに紹介します。
開発環境
開発環境では、個々の開発者が~/.dbt/profiles.ymlを使用してプロファイルを管理しています。
一方、CIおよび本番環境では、リポジトリ内のdbt/profile/profiles.ymlを用いてプロファイルが設定されています。これにより、開発環境では個別の設定が可能となり、CIおよび本番環境では一貫したプロファイル管理が実現されています。
開発用プロファイル
config: partial_parse: true vision_dbt: target: dev outputs: dev: type: snowflake threads: 8 account: account_id user: メールアドレス role: DBT_DEV database: J_CHIKAMORI # <-- Jumpei chikamori なら J_CHIKAMORI warehouse: DEV_XS_WH schema: public authenticator: externalbrowser dev_d: type: snowflake threads: 8 account: account_id user: メールアドレス role: DBT_DEV database: J_CHIKAMORI # <-- Jumpei chikamori なら J_CHIKAMORI warehouse: DEV_L_WH schema: public authenticator: externalbrowser
CI、本番プロファイル
vision_dbt: outputs: prod: type: snowflake threads: "{{ env_var('DBT_THREADS', '16') | as_number }}" account: "{{ env_var('SNOWFLAKE_ACCOUNT') }}" user: "{{ env_var('SNOWFLAKE_USER') }}" role: "{{ env_var('SNOWFLAKE_ROLE') }}" warehouse: "{{ env_var('SNOWFLAKE_WAREHOUSE') }}" database: PREP schema: public private_key_path: "{{ env_var('PRIVATE_KEY_PATH', '') }}" private_key_passphrase: "{{ env_var('PRIVATE_KEY_PASSPHRASE', '') }}" query_tag: "{{ env_var('SNOWFLAKE_QUERY_TAG', 'prod') }}" connect_retries: 3 connect_timeout: 10 use_colors: False ci: type: snowflake threads: "{{ env_var('DBT_THREADS', '16') | as_number }}" account: "{{ env_var('SNOWFLAKE_ACCOUNT') }}" user: "{{ env_var('SNOWFLAKE_USER') }}" role: "{{ env_var('SNOWFLAKE_ROLE') }}" warehouse: "{{ env_var('SNOWFLAKE_WAREHOUSE') }}" database: "{{ env_var('SNOWFLAKE_PREP_DATABASE') }}" schema: "{{ env_var('SNOWFLAKE_SCHEMA') }}" private_key_path: "{{ env_var('PRIVATE_KEY_PATH', '') }}" private_key_passphrase: "{{ env_var('PRIVATE_KEY_PASSPHRASE', '') }}" query_tag: "{{ env_var('SNOWFLAKE_QUERY_TAG', 'ci') }}" connect_retries: 3 connect_timeout: 10 use_colors: False
ドキュメンテーション
体制のところでも説明した通り、dbtモデルの開発は、基盤チームではなく各プロダクトチームのエンジニアによって担当されています。
ですが、dbtモデルの開発はプロダクトチームのエンジニアにとっての主業務ではなく、幅広いプロダクト開発の一部として行われます。そのため、dbtやSnowflakeに詳しい人だけでなく、様々なスキルレベルを持つ人々がアドホックに開発に関わっています。
このような多様なスキルセットを持つチームに対応するためには、自己完結可能なドキュメンテーションの提供が不可欠です。
そのため、以下のようなドキュメントをGitHub wikiで管理し、開発チームが必要な情報に素早くアクセスできるようにしています。
※抜粋
- CIのエラー解消方法
- ETLパターン選択ガイド
- カラムの命名規則
- クエリパフォーマンス改善
- パフォーマンス基盤改善
- リリース手順
- ログ設計ベストプラクティス
- 基盤の責任範囲
- 障害対応TIPS
- オンボーディング
- dbt
- Fivetran
- Terraform
- CDK
- Snowflake
現在、GitHub wikiの検索性や情報探索の難しさに直面しているため、ドキュメンテーションをより利用しやすくするためのサービスへの移行を検討しています。
モニタリング
モニタリングに関しては、これだけで一つの記事が書けるような内容なので、別の機会に取り上げますが、何を使っているかを簡単に紹介します。
- 基盤監視
- DataDog
- Snowsight
- データオブザーバビリティ
- elementary Cloud
- コスト監視
まとめ:変化を恐れず進化を続けるデータ基盤
この記事を通じて、私たちCARTA MARKETING FIRMがどのようにデータ基盤「Vision」を構築し、運用してきたかをご紹介しました。
現在の業務フローに合わせたアプローチを取り、dbtとSnowflakeを中心にした柔軟なアーキテクチャを実現しています。
しかし、技術は常に進化しており、ビジネスの要求も変わり続けます。過去に作成したデータ基盤が完璧であったとしても、時代の変化とともにそのアーキテクチャは必然的に変容していく必要があります。
私たちの目指すのは、ビジネスの変化に迅速に対応できる俊敏性と、同時に業務の邪魔をしない安定性を持ったデータ基盤です。これを実現するためには、継続的な学習と改善、新しい技術への適応が不可欠です。
今後も変化を恐れず、データ基盤の進化を続けていく所存です。変革の旅は終わりなく、常に次の一歩を模索し続けることが、私たちの持続的な成長の鍵となると考えています。