



【2024/06/28 追記】Elementary公式に取り上げられ翻訳記事が出ました!
概要
CARTA HOLDINGSの事業部の1つである、fluctでデータエンジニアをやっているyanyanです。 現在fluctではsnowflake + dbtを中心としたデータ基盤を構築していて、今回はその基盤のオブザーバビリティを高めるために行った施策について書いていこうと思います。
tl;dr
- fluctと、fluctが扱うデータについて
- データオブザーバビリティについて
- 具体的に行った施策について
- dbt testの追加
- Elementary OSS、Elementary Cloudの導入
- 今後の展望
fluctと、fluctが扱うデータについて

fluctは主にインターネット広告を配信するサービス (SSP事業) をメディア向けに展開しています。そのため取り扱うデータというのはまさに広告配信に関するデータです。例えば広告の表示回数やクリック回数、1回広告を表示する際の単価etc… といったものです。データの取得の仕方も色々あります。fluctが自分たちで広告表示やクリックの計測をするサーバーを用意してそこからログを吐き出したり、他社から取得したレポートデータを集計することもあります。
そういった広告データの主な用途としては以下のようなことが挙げられます。
- 広告を配信している媒体社やfluct社内の人向けに配信実績のレポートを提供
- fluctから媒体社にお金を支払う際の金額計算
- 配信制御
- etc…
現在のfluctのデータ基盤

上記のようなデータを現在どういった基盤で扱っているか。fluctのデータパイプラインはELTの形式を基本としていて、
- Extractor
- StepFunctions + ecs (go) による他社レポートの取得バッチ *自社計測のログは各計測基盤が直接S3にアップロードしている
- Load
- SnowpipeによってExtractorによってS3に上がった生データをsnowflakeにロードしている
- Fivetranによって業務システムが管理しているデータをRDSからsnowflakeにロードしている
- Transformer
- dbtを用いてSQLでデータ加工をしている
- 実行基盤はdbt Cloud といった感じになっています。
fluctのデータ基盤の課題
現状のfluctのデータ基盤に足りていないと筆者が感じていたことは、なにかデータに問題が起きたときにそれに素早く気づける仕組みでした。
とある他社データの取得に失敗したときや、dbtの実行時になにかエラーが出た際には何かしら通知が飛ぶようにはなっているのですが、データの問題というのはそれだけでは気付けないことというのがあります。
例えば、
- あるログが普段なら10分ごとくらいにロードされてるのに1時間くらいロードされてきてない!!
- dbtの加工時のロジックミスによってファントラップが起き、広告表示回数数が倍になっちゃった!!
みたいな問題が起きたときに、気づく仕組みを用意できていませんでした。 そうした問題が起きたていたときに、現状気づく方法はデータを見ている社内の人や媒体社の人からの問い合わせがきっかけとなることが多くありました。
この状態には問題が2つあり、「問題に気づくのが遅くなってしまうこと」と「データエンジニアが問題に気付けないことがあること」です。
まず、問題に気づくのが遅くなればなるほど修正にかかる時間は伸びていきます。なぜかというと、データの問題はその問題を起こしていた原因を直すだけではなく、おかしくなってしまったデータも直す必要があるからです。時間がかかればかかるほど問題の影響を受けたデータは増えていくため、直す必要のあるデータも増えていきます。
また、復旧に時間がかかればかかるほど問題の及ぼす影響の深刻度というのも増していきます。数十分や1時間程度であれば大きな問題は起きないかもしれませんが、数日続くレベルになるとユーザーからの信頼が損なわれたり、データに基づいた意思決定ができない影響で売上が低下する可能性も考えられます。
Data Observability
上記の課題を解決するべく、Data Observabilityという考えを持ち込むことを考えました。Data Observabilityという言葉は、MONTECARLOという会社のCEOが What is Data Observability? 5 Key Pillars To Know という記事で以下のように定義をしていました。
意訳すると、Data Observabilityはデータとデータを扱うシステムの状態を可視化できるような仕組みを提供する。そういった仕組みがあれば、データが間違っているとき、どこが間違っているのか、どう直せばいいのかをいち早く知ることができる。
先ほど書いたfluctのデータ基盤の課題で書いた、今のfluctのデータ基盤に足りていないことはまさにData Observabilityで、Data Observabilityを高めることによってデータエンジニアがデータの問題に素早く気づくことができ、問題の解消にかかる時間を減らしユーザーのデータに対する信頼を損なわないようにする状態を作ることができると考えました。
5本の柱
先述の記事の中で、Data Observabilityがある状態をもたらすために具体的に何を観測したらよいかという5本の柱が紹介されていました。
- Freshness: データの鮮度
- テーブルに入っているデータはどれくらい最新のものまで入っているか
- 意図しないレベルでデータの取り込みや加工が遅くなってしまっていないか
- Volume: データ量
- データ量が意図しない増減をしていないか
- Quality: データの品質
- データの取りうる値は想定した範囲に収まっているか
- プライマリキーがあるようなテーブルではレコードのユニーク性が担保されているか
- Schema: データのスキーマ
- データ構造が変化したときに来づけるか
- Lineage
- データソースやテーブルの依存関係を表したもの
- あるテーブルのデータに問題があったとき、そのデータの依存関係がわかれば影響範囲を素早く特定することができる
実際にData Observabilityを高めるためにしたこと
Data Observabilityを高めるためには、上述した5つの観点でデータを観測できるようにしていく必要があります。現状のfluctのデータ基盤では、freshness、volume、qualityの3つの観点でのObservabilityが特に足りていないと考えて、それぞれのObservabilityを高めるための具体的なアプローチを考えました。 残りの2つの観点に関しては、現状でもある程度見れたり問題が起きたら気付けるようになっていたので一旦は頑張らないことに決めました。
Schemaに関しては、dbt modelで生ログから必要な値を取り出して型をつけたり、カラム名を与えたりするレイヤーがあり、生ログのスキーマに対して破壊的な変更が起きた場合にはそのレイヤーの加工に失敗するはずです。そのため現状でも問題が起きたら気付ける状態にあると判断しました。また、Lineageに関してはdbtの実行環境をdbt Cloud上で行っており、dbt Cloudのコンソール上でdbt modelのlineageは見ることができるのでまずはそれで十分かなという判断でした。
dbt testの追加
dbtにはdbt modelやsourceに対してテストを書くことができます。(dbt testに関する公式Docs) 今までfluctのデータ基盤では一部のモデルに対してaccepted_valuesや加工の際のロジックをテストするSingularテストを書く程度で、テストを書く余地まだがありました。具体的にどのテストを足すことにしたかというと
source freshness test
dbtでは加工する前のテーブルをsourceとして定義できます。(sourceに関する公式Docs)
fluctの場合どんなテーブルがsourceとして定義されるかというと、2つあり
- S3からロードされてきた生ログや無加工の他社のデータが入っているテーブル
- ディメンションテーブルとして使うために業務システムのDBからロードされてきたテーブル
です。
今回source freshness testを追加したのは前者のテーブル群で、これらのテーブルには広告の配信実績が入っています。これらのテーブルへのロードが遅れているということはユーザーに対する広告配信レポートが遅延していることを意味します。そのためいち早く解決したい問題になります。
source freshness testを書いた大きな理由としては、testが落ちることでログの計測やExtractorのバッチ、Snowpipeに何かしらの問題が起きていると推測することができるのでdbtによる加工部分に問題があるのかそれより前段に問題があるのかを素早く切り分けられるというのが大きかったです。

not null test
次に、カラムのnot null testを追加しました。あらゆるモデルにnot null testを追加していてはキリがないので、sourceから加工に必要なカラムを抜き出したり、最低限のリネームをする層にのみ追加しました。 また、その層のモデルの中でもこのカラムがnot null だと後段の加工や集計で困るレベルのものにまずは絞って追加することにしました。
Elementary OSS + Elementary Cloudの導入
dbt modelの実行状態やfreshness、volumeの異常検知、lineageなどを1つの場所で見れるようにするべく、Elementary (https://www.elementary-data.com) というdbt packageと、Elementary CloudというSaaSツールを導入しました。
elementaryはdbt nativeなツールで、Data Observability を高めるためのdbtのテストを簡単に追加できるdbt packageがOSSとして提供されています。また、Elementary Cloudではそれらのテスト結果やlineageなどを一覧できるダッシュボードのホスティング環境であったり、アラートや自動での異常検知といった機能を利用できます。
elementary以外にもSaaSのData Observabilityツールというのはあったのですが、
- 値段
- dbt nativeで組み込みやすい
- 社内で導入事例があるため知見共有できる
- automated anomaly機能を使いたかった
といった理由からelementary Cloudを導入することに決めました。筆者としては特にautomated anomaly機能を使えるのがCloudを使いたい理由として大きくありました。
OSS版でもanomaly testというのは書くことができるのですが、設定しなければいけないパラメータがたくさんあります。モデル1つ1つに対してanomaly testを手で足していくのはあまり現実的ではないと考えていたため、それらの設定を一切することなくanomaly testをしてくれるというのはかなり助かりました。

このようにダッシュボード画面でdbt modelやtestの実行状況、freshnessやvolumeなどの状態を一覧することができます。また、ダッシュボードからより詳細な情報を見ることもできて、例えば以下の画像はautomated volume testでwarningが出ているモデルの詳細なのですが、volumeの推移を見たりすることができます。
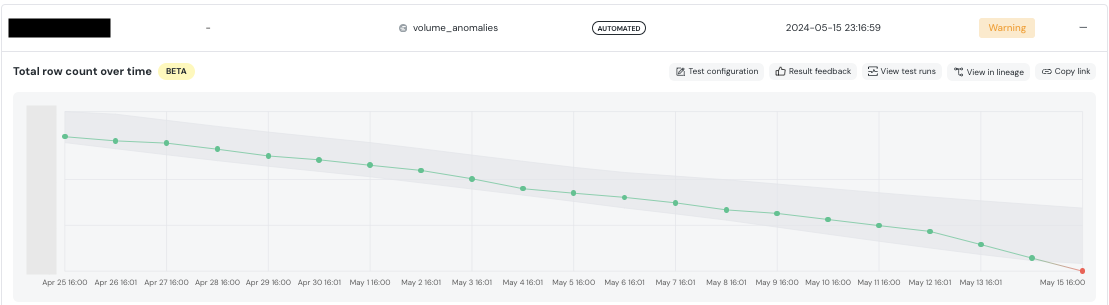
他にもdbt modelのlineageを見れる画面もあります。そこではただmodel間の依存関係が見れるだけではなくカラムレベルのlineageを追うことができたり、モデルに対するテストの実行結果というのも参照することもできます。
今後の展望
dbtのtestを足したり、Elementaryが提供するdbt packageやSaaSツールを導入することによってfluctのData Observabilityを提供する第一歩を踏み出すことができました。現状、freshnessやvolume、not nullなどの最低限のquality、lineageの一覧などはできるようになったので以前よりもデータの問題に素早く気づけたり問題の原因を把握しやすくなりました。一方で、schemaの変更検知であったり、qualityのテストはまだnot nullしか書けていなかったりとさらにObservabilityを高める余地は残されています。 elementaryの導入をしてからまだ実際にデータに関する問題が起きたりはしていないため、運用してみて役に立ったかとか、課題というのはこれからという感じです。