



 こんにちは、株式会社CARTA MARKETING FIRMのデータエンジニア、@pei0804 です。
こんにちは、株式会社CARTA MARKETING FIRMのデータエンジニア、@pei0804 です。
2022年に生まれたCARTA MARKETING FIRMのデータ基盤Visionがどのような背景から生まれ、進化してきたのかを振り返り、Visionの"Why"を残す試みです。
2020年:レポート基盤刷新プロジェクト
Visionの前身となるプロジェクトが、2020年にCARTA MARKETING FIRM(当時はZucks)の新DSP立ち上げをきっかけに、既存のレポート基盤刷新プロジェクトが始まりました。
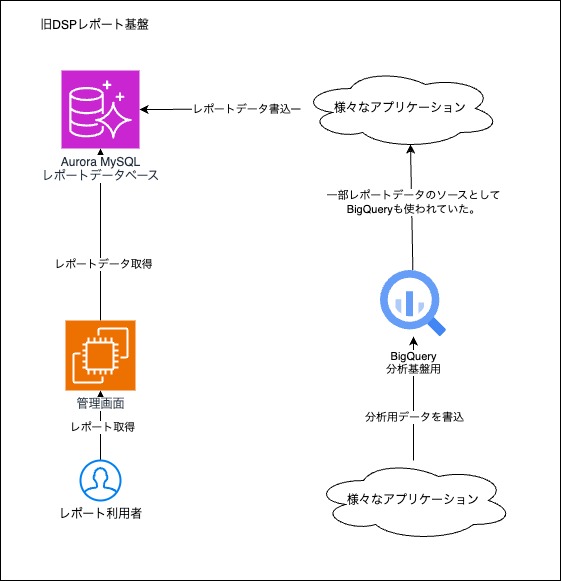
図: 旧DSPのレポート基盤
旧DSPのレポート基盤には以下のような問題がありました。
- レポートの軸を増やすことが難しい。
- データソースが分散していて数字がズレる。
- トラブル発生時の再取り込みが困難。
これらの問題を根本的に解決するため、アーキテクチャやデータストアの選定から見直すことにしました。
2021年:Redshiftベースのレポート基盤が稼働
Redshiftをベースとしたレポート基盤が出来上がり、動き始めました。
この基盤を構築する上で、重要だった意思決定は、列指向データベース、ラムダアーキテクチャ、ディメンショナルモデリングの採用です。
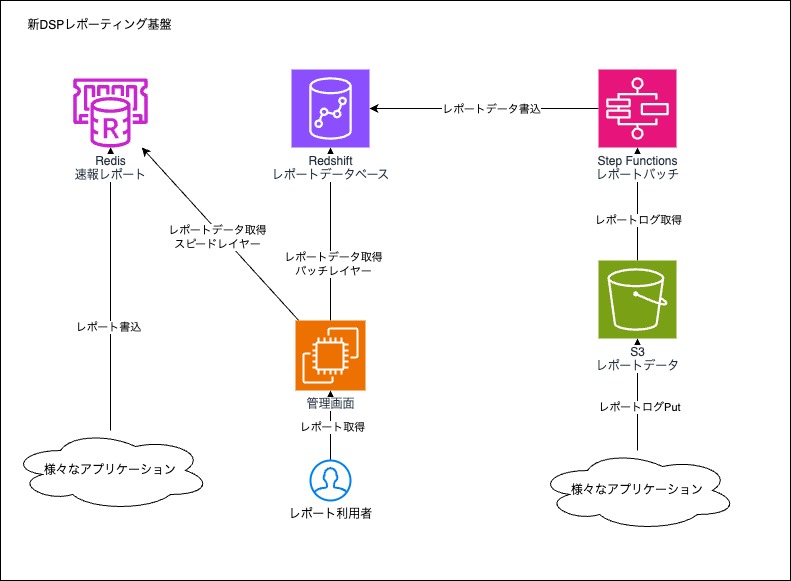
ラムダアーキテクチャの採用
従来のレポート基盤は、ほぼ全てがストリーム処理で組まれていたため、運用が非常に難しいものでした。
業務を紐解いていくと、速報性と正確性を同時に応えようとした結果、このようなアーキテクチャになっていることがわかりました。
しかし、実際にはそれぞれ分けて考えることで解決できる問題であったため、バッチ処理とストリーム処理を組み合わせたラムダアーキテクチャを採用しました。
これにより、それぞれのワークロードに適したアーキテクチャを実現することにしました。

図: アーキテクチャの見直し
また、バッチレイヤーにワークフローエンジンを導入することで、データの依存関係を明確にし、再集計のしやすさを向上させました。

ちなみに、元々はcronを組み合わせてジョブを表現しているような状態で、依存関係を読み解くのが難しく、簡単に運用できるものではありませんでした。

列指向データベースの採用
以前は、行指向のAurora MySQLと列指向のBigQueryを併用していましたが、データソースの分散によって数字のズレが発生していました。
元々はAurora MySQLだけでレポートを提供していたところ、行指向に不向きな処理をやらせていたため限界に直面し(主に集計パフォーマンスとカラム追加の難易度)、分析用途で作られていたBigQueryに一部のレポート機能を移管せざるを得ない状況になっていたのです。

図: カラム追加ができない
そこで、列指向データベースであるRedshiftに一本化し、集計パフォーマンスとカラム追加の柔軟性を向上させました。
当時、Redshiftを採用した理由としては、想定していたワークロードがレポートのみだったため、スパイクが発生するようなワークロードよりは、料金が一定で安定したパフォーマンスを提供できるRedshiftが非常にマッチしていたからです。
ディメンショナルモデリングの採用
実はアーキテクチャの刷新と列指向の採用だけでは、思った以上に劇的な改善は見られませんでした。
確かに、集計パフォーマンスも上がり、運用負荷も軽減したわけですが、最終的にクエリを発行する部分は、既存のレポートと同様に複雑なクエリになってしまうという問題が残りました。
当時、これに対するノウハウが社内に存在せず、日本語情報でもそれらしい情報を見つけることができなかったので、洋書を何冊か読んだところ、ディメンショナルモデリングなるものと出会いました。
これを適用すれば、クエリの複雑性の問題が解消できることがわかりました。
何故ならクエリが辛いのではなく、モデルが辛いことが原因だったからです。

ですが、ここで一つの問題に直面します。 モデリングを行う人が属人的になるというリスクです。何故なら社内に知見がないのと、日本語情報で実践で使えるレベルの情報がないからです。
そこで、日本語でモデリング記事を世に出してみる活動をし始めたのは、この頃です。 これにより、誰でも日本語話者がディメンショナルモデリングとは何かを、少し実践的な内容で理解できる土壌を用意することで、社内外に仲間を増やすことにしました。
2024年現在、社内でディメンショナルモデリングを理解して扱える人材が増えているので、この活動はうまくいったと考えています。
このプロジェクトで起きた変化
| 課題 | 解決策 |
|---|---|
| レポートの軸を増やすことが難しい | 列指向データベース(Redshift)の採用で、カラムの追加が容易に |
| データソースが分散し数字がズレる | データソースをRedshiftに一元化し、Single Source of Truth(以下SSoT)を実現 |
| トラブル発生時の再取り込みが困難 | バッチレイヤーとワークフローエンジンの組み合わせで、再集計がしやすい仕組みに |
| クエリが複雑になる | ディメンショナルモデリングの採用で、クエリの複雑性を最小限に |
関連資料: - ぼくのかんがえる最高のレポート基盤
2022年:データサイロ化の問題とSnowflakeの採用
レポート基盤の安定稼働とdbtの導入
レポート基盤が一年ほど運用され、特に問題なく稼働し続けました。さらにdbtとの出会いもあり、データ変換処理の複雑性の問題も解消され、順風満帆でした。


データチームの課題と水平垂直協調の導入
しかし、CARTA MARKETING FIRM(当時はZucks)内でデータに関する問題が、別のチームで発生し始めました(正確には前から問題はあった)。 それが、当時データを活用した課題解決を行うチームの業務のほとんどが、本質的な業務以外のところで疲弊しているという問題でした。 このチームは、一般的にはデータチームやAIチームと呼ばれることが多いので、ここではデータチームと呼ぶことにします。
コードを一通り読んだところ、使っている分析基盤とデータパイプライン、モデリングに問題があることがわかりました。 また、業務範囲にも課題がありました。当時のデータチームメンバーが得意・力が出る領域は、データサイエンスであって、ソフトウェア開発ではないという性質が一定ありました。
これに対して、ソフトウェア開発に関する部分は、適宜他チームのエンジニアに相談しようよというのもあったのですが、組織図通りにコミュニケーションが分断(コンウェイの法則)されていました。

そこで、自然に協調し、ソフトウェアエンジニアと会話が発生する状態を作るために、チームにエンジニアをアサインし、データサイエンス業務をエンジニアリングしていくことにしました(後にデータエンジニアと呼ばれるロールになる)。
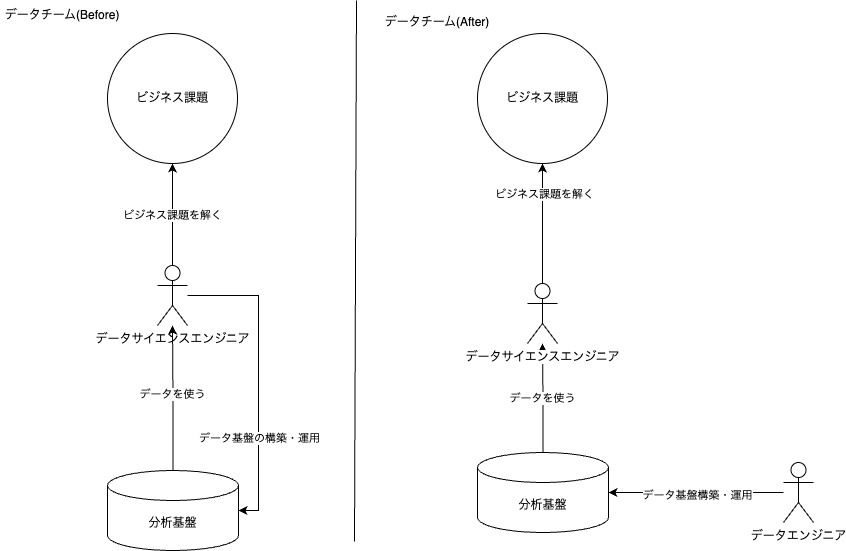 図: データエンジニアがデータサイエンス業務を仕組み化する
図: データエンジニアがデータサイエンス業務を仕組み化する
この体制を水平垂直協調(データエンジニアとデータサイエンティストの協力体制)と呼んでいます。 データエンジニアはデータに関連する業務を仕組み化し(水平方向の力)、データサイエンスメンバーはデータエンジニアが作った仕組みを使って、ビジネス課題を解決します(垂直方向の力)。

図: 得意領域で協調する
これにより、データサイエンス業務がエンジニアリングされる体制になり、業務効率化への道筋が見えるようになりました。
詳しい話は、データをモデリングしていたら、組織をモデリングし始めた話 でまとめています。
複数ワークロード、プロダクトのサイロを破壊するべくVisionが爆誕
弊社には、大きなプロダクトとして、アドネットワークとDSPとアフィリエイトがあります。 それぞれのプロダクトには、それぞれのレポート基盤があります。そして、分析用の分析基盤は別途あります。 こういった状況で起きる問題としては、以下のようなものがありました。
- レポート基盤が分かれているため、プロダクトを横断した分析が難しい。
- 分析基盤にはあるけど、レポート基盤にはないデータが発生。その逆も発生。
つまり、欲しいデータがプロダクト、ワークロード(レポート、分析)を横断するとサイロ化している問題がありました。
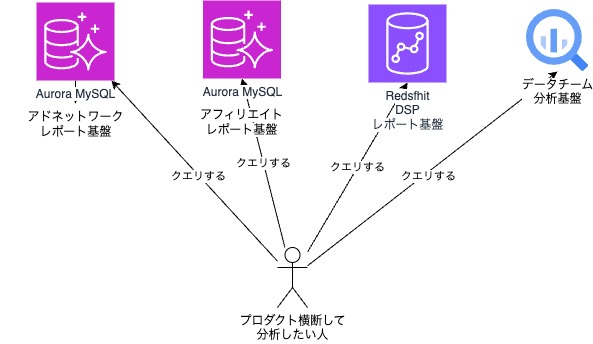
図: プロダクト・ワークロードを横断すると、データ取得が大変

図: データソースの分散
この問題は、前々から認知はしていたものの、レポートと分析では、クエリの性質や求められる要件が違うため、RedshiftかBigQueryのどちらかに全てを寄せれるイメージがありませんでした。
そこで、全く違う選択肢を模索し始めることにしました。

図: BigQueryとRedshift両方の強みを持ったDWH
そこで新たに採用されたのがSnowflakeです。
全てのデータをSnowflakeに集め、そこにアクセスすれば、全てが横断的に把握可能な世界線を作ろうということで、Visionが爆誕しました。
そして最終的な着地はこのアーキテクチャに。
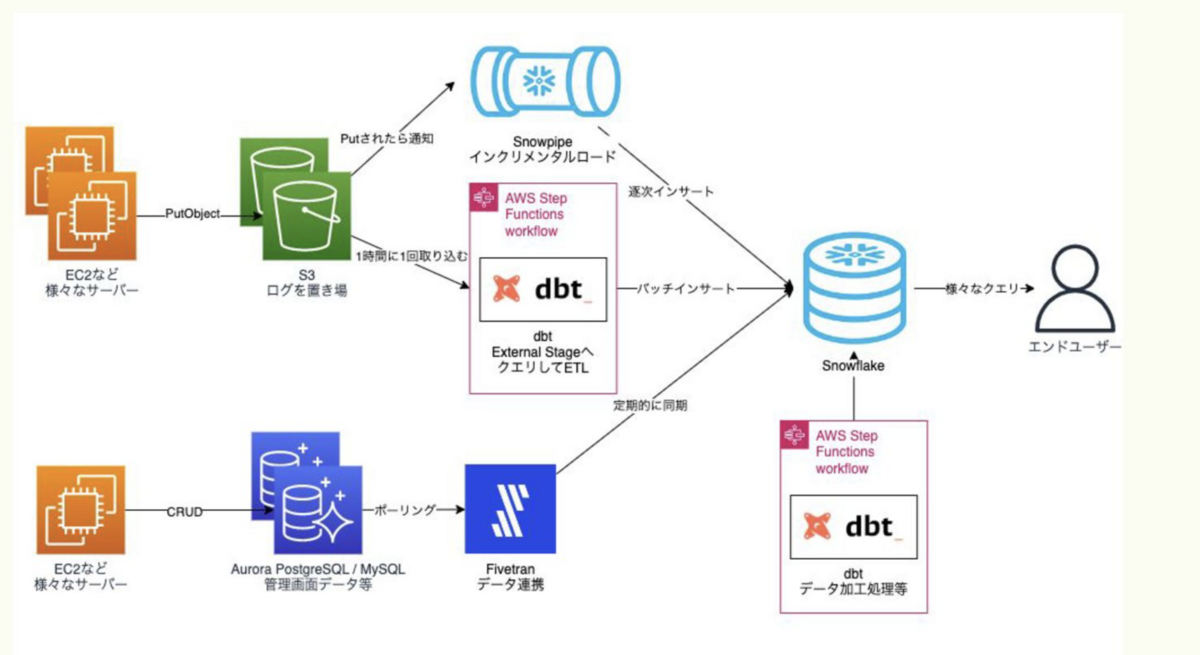
詳しい話はぼくのかんがえる最高のデータ分析基盤 / strongest-data-architecture-discussion でまとめています。
2023年:Visionの進化と活用範囲の拡大
採用、DataOps、DataObservability、etc...
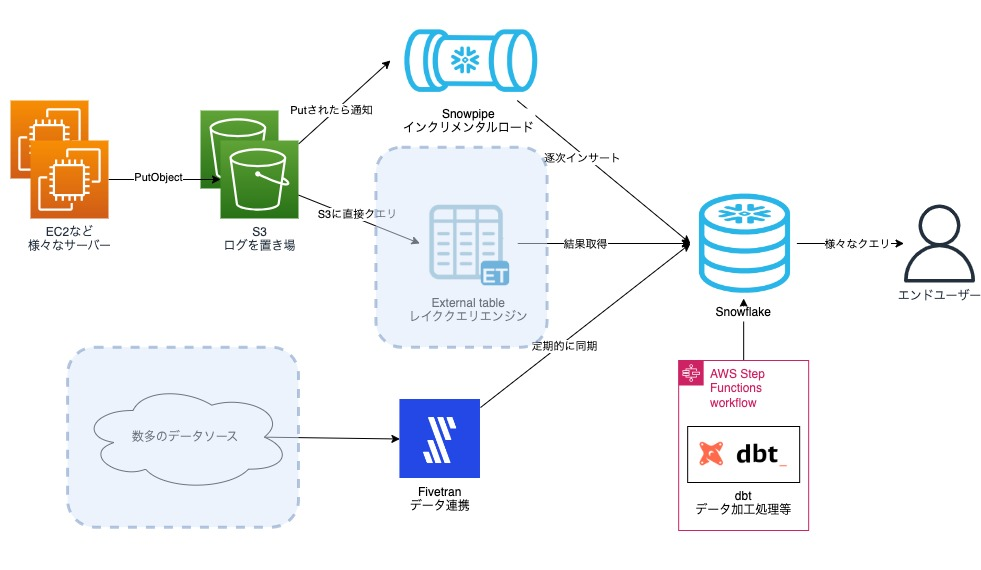 図: 2023年時点の構成図
図: 2023年時点の構成図
2023年に入り、Visionでは様々な取り組みを行いました。 特に重要だった取り組みとしては、採用とDataOpsの導入です。
採用に関しては、新卒からのスタートという非常にチャレンジングな取り組みでした。配属後は実務と座学を積極的に行い、わずか1年足らずで顕著な成果を上げ、データ基盤の強化に大きく貢献しています。
一方、Visionの利用者も増えたことで、中央集権的な体制では限界が来たこともあり、自然とDataOpsへのシフトが必要になりました。 まだ課題は残りますが、基盤チームと利用者それぞれが本来発揮したい価値に集中できる体制ができつつあります。

参考記事:
- Snowflakeと共に過ごした一年間。その進化過程と未来へのVision
- Snowflakeの力を引き出すためのdbtを活用したデータ基盤開発の全貌
- 中央集権体制からDataOpsへの転換
- 2024年に描く青写真(データアーキテクチャ)
- dbt x snowflakeで使っていないテーブルとビューを安全に一括で削除する
2023年10月1日に4社が統合しCARTA MARKETING FIRMのデータ基盤へ
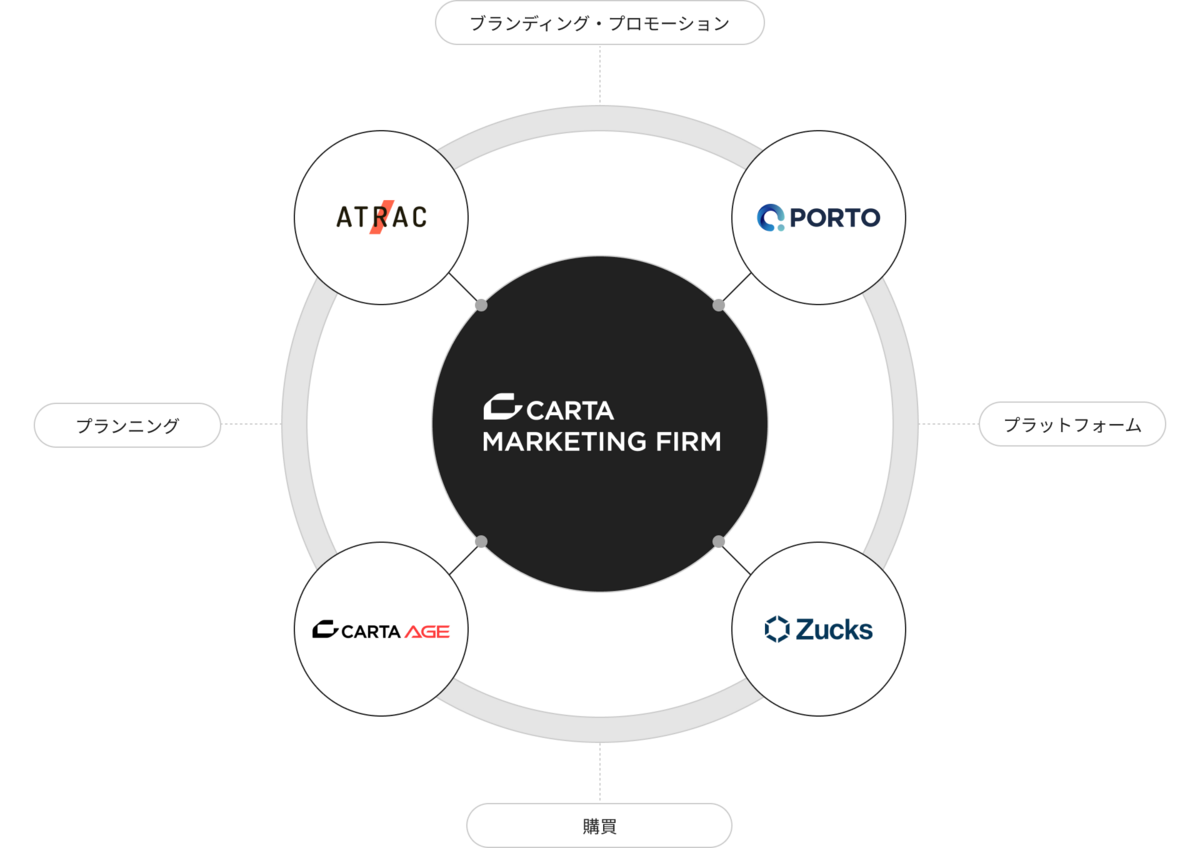
図: 4社統合
2023年10月1日、4社が統合してCARTA MARKETING FIRMが誕生しました。 これにより、Visionは特定のプロダクトのレポート基盤から、自社のデータ基盤を経て、CARTA MARKETING FIRMのデータ基盤へと進化を遂げました。
しかし、この統合により、元々別会社で運用されていたデータが、そのままデータのサイロとなり新たな課題として浮上しています。
データの統合や整理など、解決すべき問題は山積みですが、これは同時に、より大きな価値を生み出すチャンスでもあります。
私たちは、このチャレンジに真正面から向き合い、CARTA MARKETING FIRM全体のデータ活用を推進していく所存です。
まとめ:データ活用の道のりはまだ始まったばかり
Visionは、単なるレポート基盤から始まり、データの一元管理、DataOpsの導入、データオブザーバビリティの実現など、着実に進化を遂げてきました。
しかし、これはデータ活用の道のりの始まりに過ぎません。技術の進歩とビジネス要件の変化に伴い、Visionも常に変化し続ける必要があります。俊敏性と安定性のバランスを保ちつつ、新しい技術を取り入れ、データ駆動型の意思決定をさらに推し進めていくことが求められます。
Visionの価値は、データの力を最大限に引き出し、ビジネスの成長を加速させることにあります。その実現のためには、継続的な改善と挑戦が不可欠です。過去の成功に満足することなく、常に次のステップを模索し、前進し続けることが重要です。
「事業の正のレバレッジになる。」をミッションに、これからもVisionは進化を続けていきます。