



TL; DR
- CARTA MARKETING FIRMでは、データサイエンティストが本質的な価値創出に専念できる分業体制を目指す過程にある
- Snowflake中心のデータ基盤を活用しながら、プロダクトチームがプロダクト要件に合わせたデータ設計を行える組織体制を実現
- プロダクトチームとデータサイエンティストが密接に協業しプロダクトドメインを吸収できるチーム体制へ移行
- データサイエンティストが開発したモデルを短期間で検証・実装・改善するフィードバックループを実現できる環境を整備しつつある
CARTA MARKETING FIRMとは?
CARTA MARKETING FIRMでは、”クライアントの事業を進化させる”をミッションに、以下4つのサービスを運営しています。
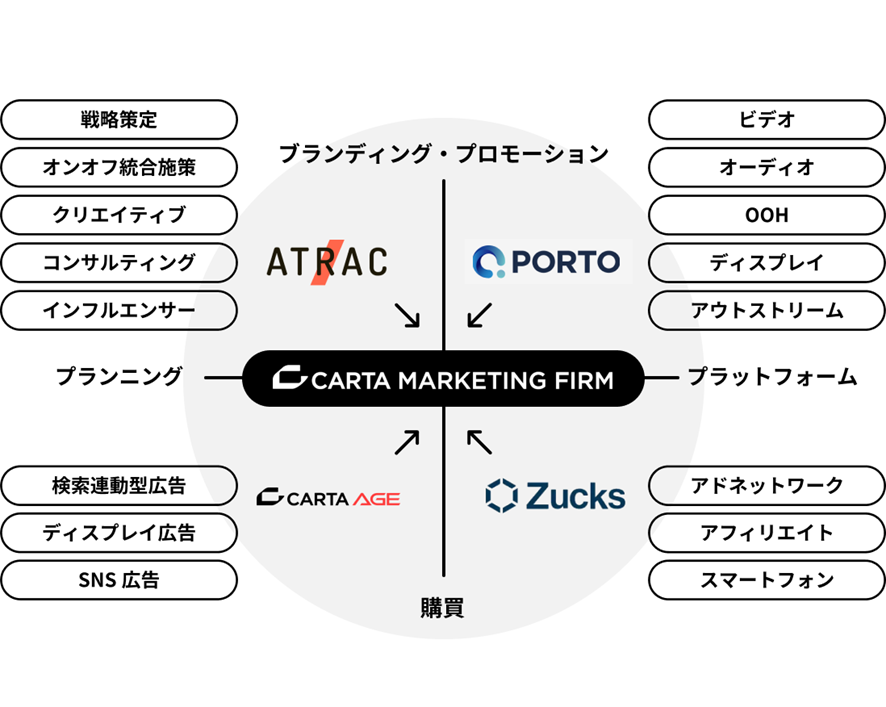
- 広告代理事業を展開する「ATRAC」と「CARTA AGE」
- 国内最大級のスマートフォンアドネットワークやグローバル広告主向けに広告代理事業を展開する「Zucks」
- ブランド広告主向けアドプラットフォーム「PORTO」
その一つであるZucksは、アドネットワーク、デマンドサイドプラットフォーム(DSP)、アフィリエイトの3領域でプロダクトを提供するマルチプロダクト・サービスです。
今回は、 特にZucksにおけるDSP事業のデータエンジニアリング・データサイエンス領域の変遷を扱います。
見るべき領域が広いデータサイエンティスト
Webサービスが進化するにつれて、計測可能なデータ量は増加しています。広告領域では特に効果計測の側面から広告パフォーマンスを計測し、効果改善につなげるサイクルを高速に回す必要があります。ビジネスに利用できるデータセットが揃う一方で、それを意味のある形に変換しビジネス判断に有用な知識に変える必要性が更に高まっています。

それらを適切に扱うため、データサイエンティスト(以下、DS)に求められる業務範囲は拡大しています。その業務フローはおおむね以下のように分けられるでしょう。
- データ収集:MLモデルを構築するために必要なデータを収集する
- データクリーニング:モデルトレーニングで使用するためのデータを前処理
- データ探索:モデル設計に役立つデータを分析し、理解
- モデル構築とトレーニング:準備されたデータを使用してMLモデルを構築し、トレーニング
- モデル評価:モデルのパフォーマンス評価
- 継続的デリバリー:モデルを本番環境に展開する
- モニタリング、A/Bテスト:モデルのパフォーマンスを追跡し、最適化のためのA/Bテストを実施する
これまでのZucksとデータ領域における課題
Zucksのプロダクト黎明期では、1人のデータサイエンティスト(+インフラエンジニアからのサポート)がこれらすべての領域をカバーしていました。つまり1人がプロダクトデータ収集、分析のためのデータパイプライン構築、MLモデルの実装、プロダクトへのリリースまですべてを担当していました。(下図におけるDS,MLの両方を指す)
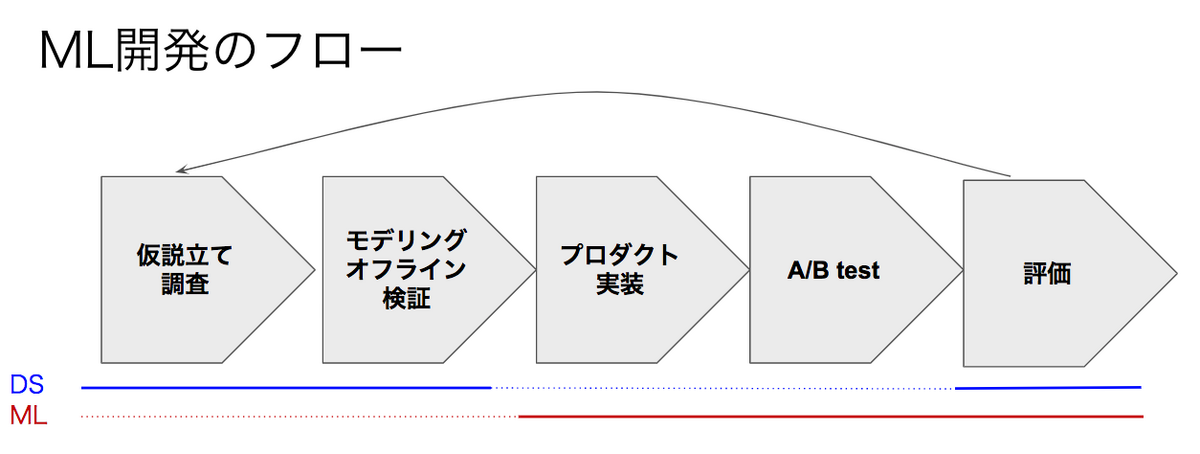
引用元: データサイエンティストはどこまでエンジニアリングをすべきか?
しかし、このアプローチではプロダクト戦略に基づく意思決定、モデルを生成、プロダクトへの実装、有用なフィードバックサイクルを高速に回すことが難しい状況でした。
また、サービスの進化に伴い、マルチプロダクト化を経たことで、一人のエンジニアが担当する領域が拡大しました。その結果、中央集権的な体制ではプロダクトドメインの知識をキャッチアップする難易度が高くなりつつありました。
現在のZucksとデータ領域
分業体制とデータ基盤の構築
データサイエンティストはその特質上、「データにまつわるすべての仕事」を一挙に担うことが求められがちである
この課題に対してZucksは、試行錯誤の末、データ領域における業務を分業制にシフトしています。現在は移行中で、データサイエンティストがより本質的な仕事に向き合う体制を構築する過程にいます。
データ領域における技術選定は以下。
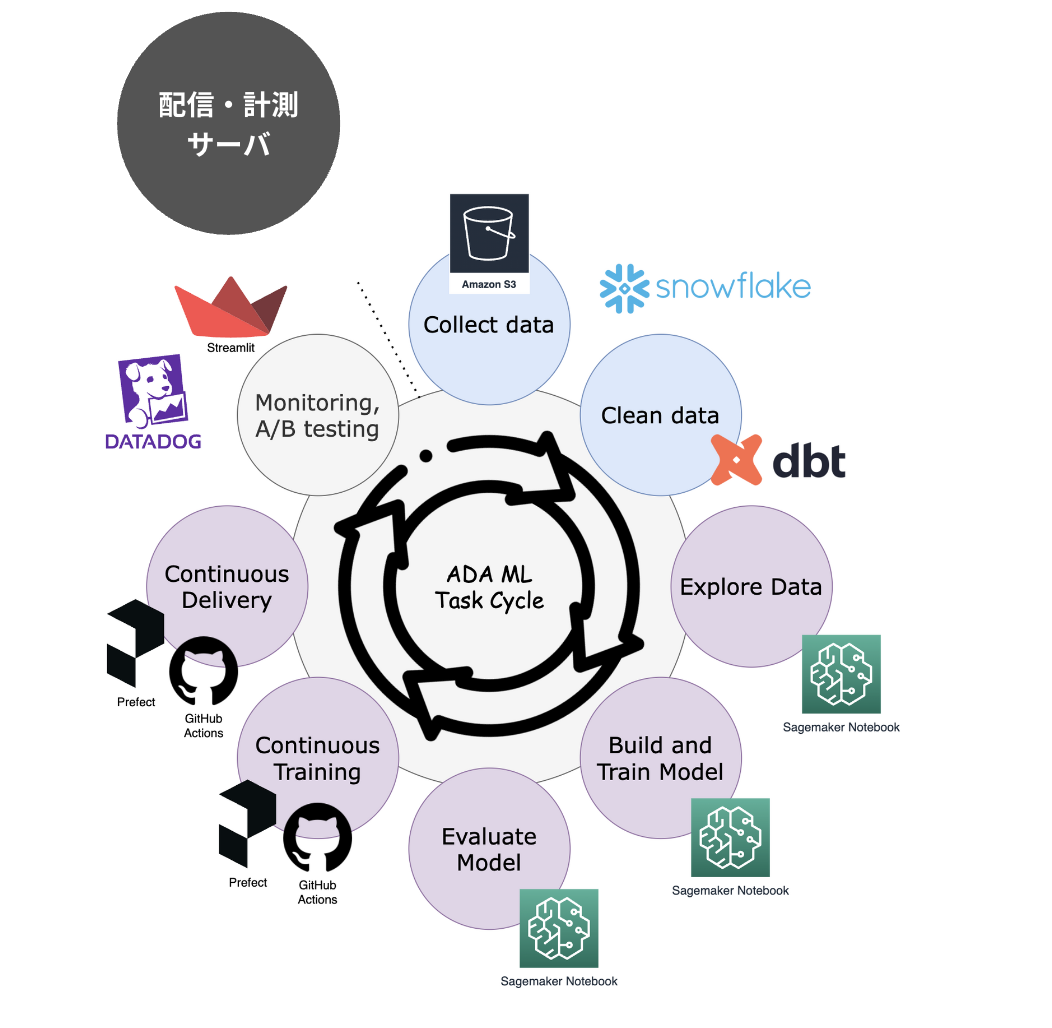
特にモデルのCI/CDにおいてはPrefectとGitHub Actionsを導入しています。 煩雑であったモデルのCI/CDにおけるIaC管理コストや認知負荷の高いソフトウェア開発のキャッチアップの必要性を可能な限り抑えることで、データサイエンティストがモデル実装やモデル検証実験に割ける時間を創出しています。より本質的な仕事に向きあえる基盤が整いつつあります。
分業体制は以下のようにしています。
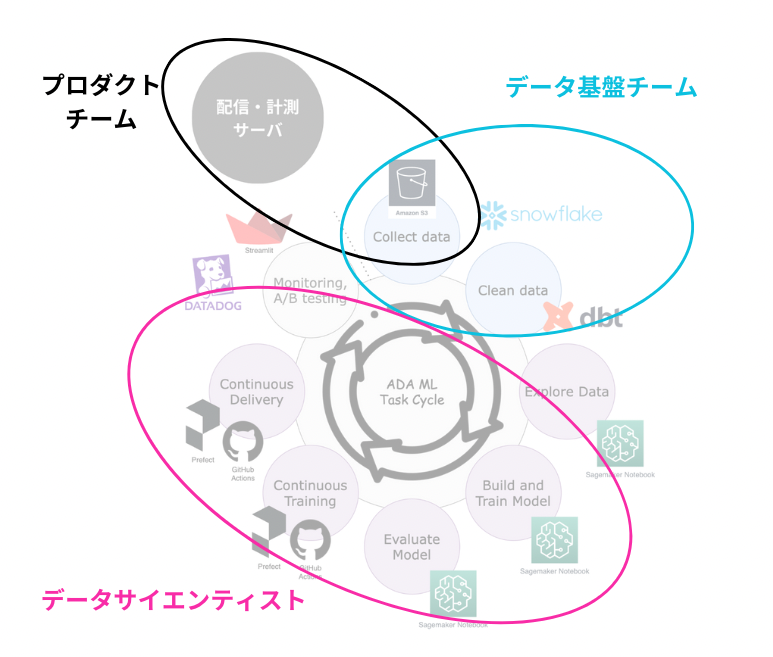
データ基盤チーム
- 広告配信・計測サーバと紐づくデータ基盤構築および保守管理、プロダクトチームとの協業
データサイエンス
- データ探索
- モデル構築とトレーニング
- モデル評価
- 継続的デリバリー
- A/Bテスト・モニタリング
- 配信サーバへの実装
- プロダクトチーム(DSP)
- 管理画面および広告配信・計測サーバの開発
- 配信データ・実績のデータ収集およびモデリング
チームにおける役割分担
個々の役割はどのように分けているでしょうか?
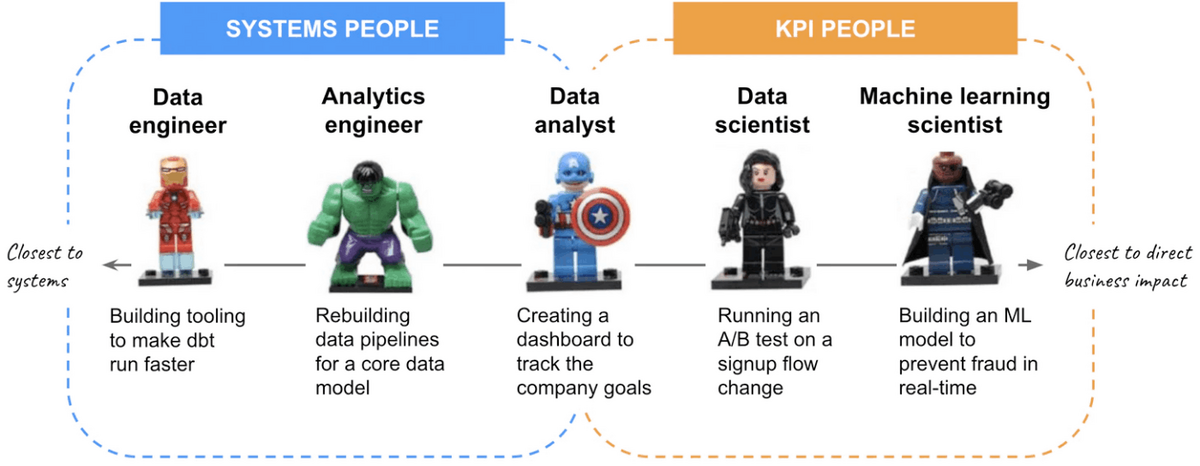
引用: How to think about the ROI of data work
上記の記事ではKPIを指標にその役割を解説をしていますが、ここでは データチームの役割を端的に表す区分のみに着目 をします。
企業のフェーズやプロダクトの要求によりますが、データ領域に関するエンジニアリングの役割を分割すると、大枠このような構成に分けられるのではないでしょうか。
- Data Engineer:
- データをData Warehouse (DWH)に集約し、ETLを行うデータパイプラインの構築
- Analytics engineer
- DHWに格納されたデータを利用する分析基盤の構築
- Data analyst
- 分析基盤を使った分析・プロダクト戦略の立案
- Data scientist
- 戦略に沿った学習モデルの構築およびA/Bテスト
- Machine learning scientist
- 選定された学習モデルをプロダクトに実装
- モデルの継続的なCI/CD
これらの役割がきっちりと分かれているケースは少なく、さまざまなケースがあるでしょう。
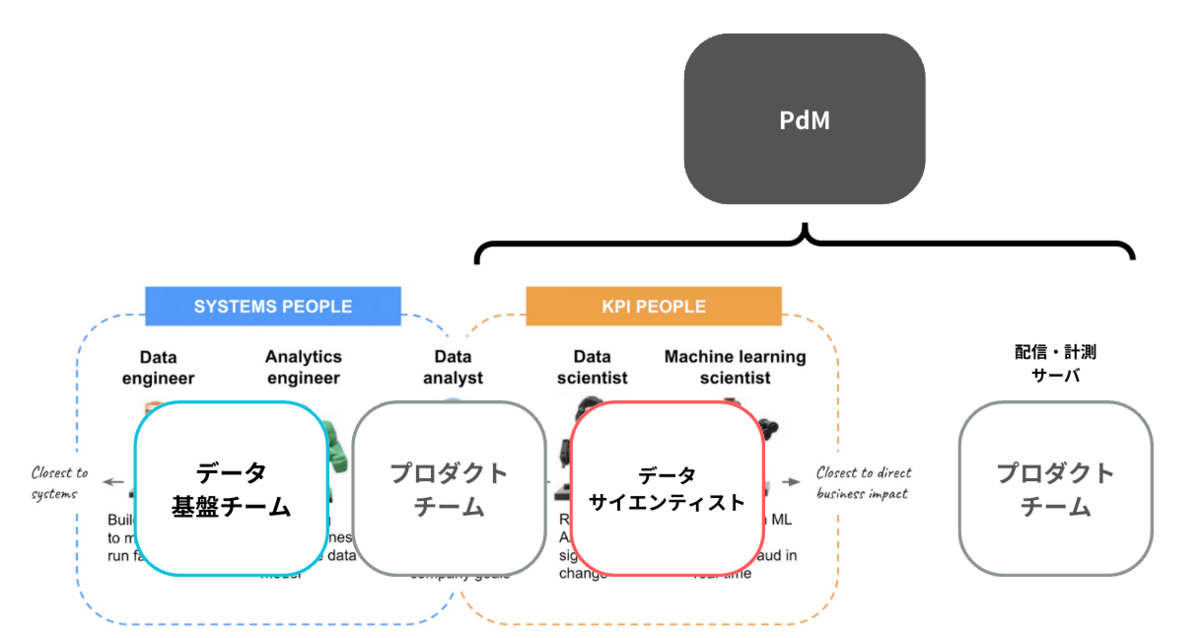
現在のZucksは、その体制を変更し、各領域に主担当を置いた分業体制に移行をしています。これによってデータサイエンティストがより本質的な価値を生み出すことに集中する環境が整ってきました。
特にデータ基盤への取り組みについて、詳しくはこちらをご覧ください。
現在のZucks ープロダクトチームとデータサイエンティストの協業体制ー
サービスの進化により、マルチプロダクト化によって担当領域が増えた
この課題に対して、Zucksでは「プロダクトチームの一員として機械学習エンジニアがコミットする」方針をとっています。
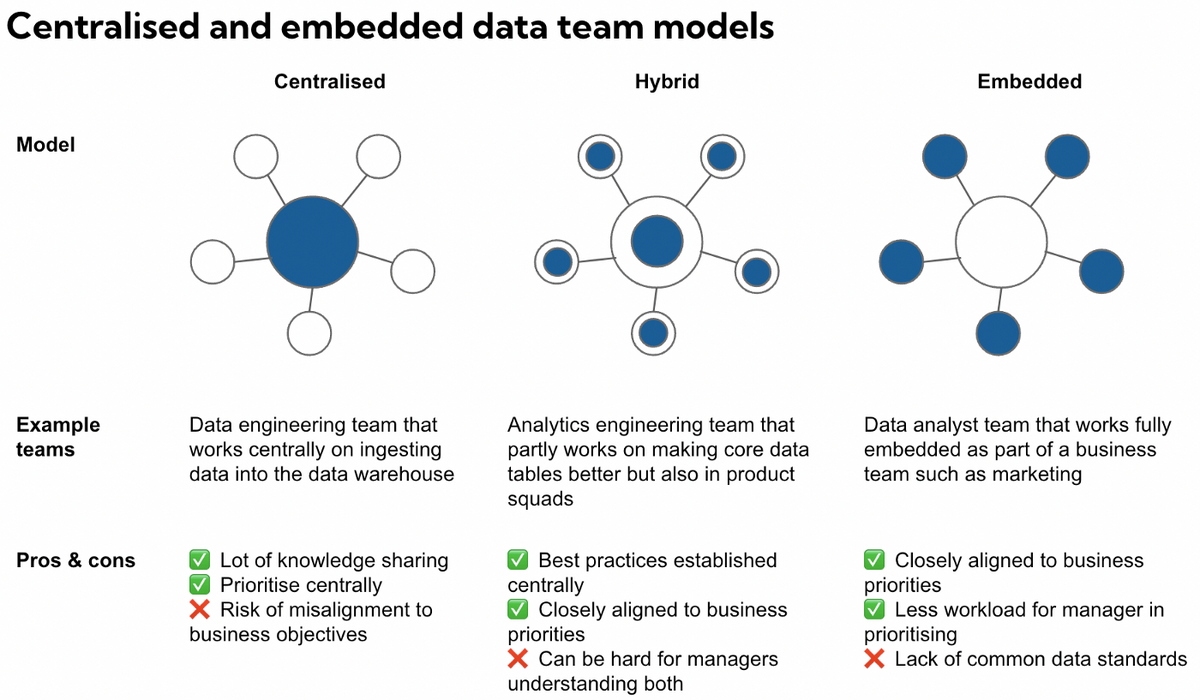
Data team structure: embedded or centralised? | by Mikkel Dengsøe | Medium
現在のZucksでは、中央集権的であった体制からプロダクトチームと共に価値を創出するEmbeddedチームモデルを採用しています。データサイエンティストがプロダクトチームの一員として価値を発揮することでコンテキスト共有を容易にし、高速にフィードバックサイクルを回せる体制を取っています。