




初めまして!この度24新卒エンジニアとしてCARTA HOLDINGSに入社しました、そーやです!事業部はCARTA COMMUNICATIONS(CCI)所属となります!
今回はCARTA HOLDINGS(以下、CARTA)のエンジニア新卒研修の1つ、OpenAIハッカソン研修にて、外部ライブラリを用いず(embeddingを除く)、自作したRAG(Retrieval-Augmented Generation)を用いた社内ポータルサイト版ChatGPTを制作したので、その紹介となります!
新卒OpenAIハッカソン研修とは?
CARTAでの新卒エンジニア向けの研修です!OpenAI社が提供しているAPIを用いて、半日で何か作ってみよう!という研修となります。
| 時間 | 内容 |
|---|---|
| 10:00~11:00 | OpenAIハンズオン |
| 11:00~16:00 | チームに分かれ開発 |
| 16:00~17:30 | 成果発表 |
| 17:30~18:00 | 総評 |
まずは10:00~11:00頃までOpenAIの使い方を学びます。OpenAIのAPIキーを配布して頂き、皆んなでデモアプリを動かしていきます。ここで色々遊んで一通り使い方を学んだ後、3人1チームに別れ、ハッカソンを行っていきます。僕は同期のアトム・やなぎと同チームになりました!

DIGITALIO配属、めちゃ筋肉が強い。筋トレに困ったら彼に聞くことにしている。今回はSlackBotの実装をしてくれました!
テレシー配属、イケメン有能データサイエンティスト。AIにとても強い。 テレビの視聴率ってちゃんと測れてるの? - CARTA TECH BLOG

ハッカソンでの開発物は「OpenAI APIを用いる」が満たされていれば基本なんでもOKです。レギュレーションは以下の通りでした!
- モデルは以下を使う
- gpt-3.5-turbo
- gpt-4-turbo-preview
- gpt-4
- gpt-4-turbo-2024-04-09
- ウェブアプリでもいいし、cliツールでもいいです。OpenAI APIをつかえばOK。
- ローカルで動けばOK
- デプロイは今回はなし(時間もないので)
- 評価は特にしません〜ぜひ面白いツールをつくってみましょう
- もちろん公序良俗に反するものはNG
開発は~16:00なので、アイデア出しの時間も含めて5時間で何か作らなければなりません!意外とタイトなので時間内で開発できてインパクトありそうなアイデアを考えるのも重要です。
16:00~は各チームで発表を行なっていきます。他チームも面白い開発ばかりで聞いててとても楽しいです。自己紹介から新卒のクラスタリングをしてみたり、slackでの直近の発言から自己紹介を自動生成してくれたりと、、、皆んな発想がすごい!となりました笑
我々のチームの制作物
CARTAでは、オフィスに関する情報や申請についての情報など、社内情報がまとめられているポータルサイトとして、「CARUUPE」というものが存在します。オフィスに関する大抵のことはCARUUPEを見れば解決します。問い合わせ担当者の負担を減らすためにも、オフィスに関する不明点はまずCARUUPEで調べる、という運用が行われています。
とはいえ様々な情報がまとめられているので、欲しい情報をピンポイントでCARUUPEから探すのには苦労することもあります、、。探す時間ももったいないから、「雑に自然言語で情報問い合わせれたら便利そうだな〜」と研修を受けて感じていました。
そこで、便利そうだと感じるなら作ってしまえ!社内便利ツールになるし、OpenAIハッカソンのネタに丁度いいじゃん!!ということで、今回はSlack上で動作するCARUUPE版 ChatGPT SlackBotを作成しました!
以下のように、SlackBotに対してメンションして質問を投げると、CARUUPEの内容から情報を検索し、botが答えてくれます!情報が載ってるCARUUPEページも載せてくれます。
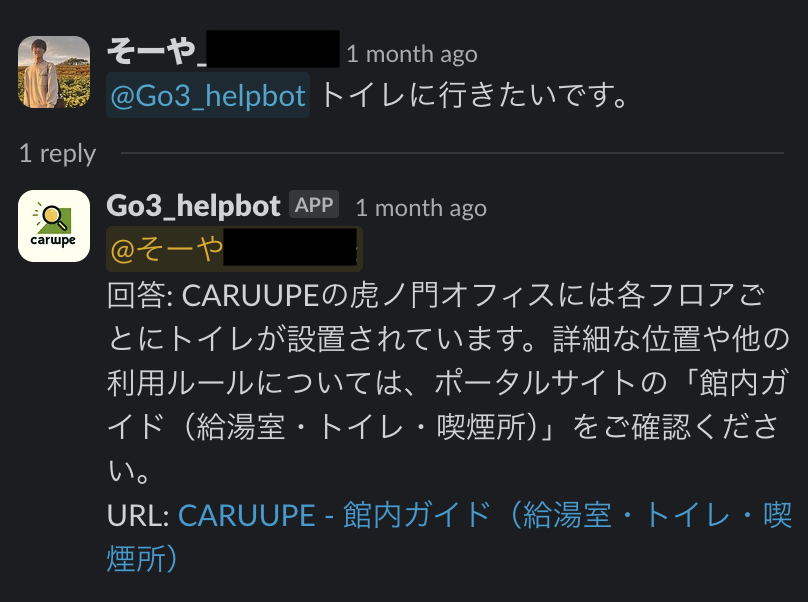
実現したいことは
slack上でbotに問い合わせしたら、CARUUPEから情報探して答えてくれる。
となります!
そしてこれを達成するために実装することは大きく3つに分けられます!
- Slack botの作成
- CARUUPEからページテキストを取得
- 質問に対する答えを探す
1.Slakcbotの作成をアトムが担当、2.CARUUPEからページテキストを取得を僕が担当、3.質問に対する答えを探すをやなぎが担当といった割り振りで開発を進めていきました!
今回はその中でも2,3について実装を紹介していきます!
CARUUPEからページテキストを取得したい
CARUUPEはその実態はGoogleサイトというGoogleのサービスを使用して作成されたインターネットサイトとなっています。Googleサイトからページテキストを直接取得するAPIなどは用意されていません。そこで今回はWebスクレイピングを用いてCARUUPEから情報を取得しました。
Googleサイトなので、Googleアカウントにログインし認証を突破する必要があります。ここはもうブラウザでログインするのが早いので、今回はPythonのSeleniumを用いてGoogle Chromeをオートで操作しスクレイピングを行います。
Google Chromeにはプロファイルというものがあります。Google Chromeのプロファイルを使うことで、一度ログインしてしまえば二度目以降はログインページをスキップして直接スクレイピングが可能になります。ChromeDriverではprofile-directory及びuser_data_dirオプションを指定することにより、プロフィールを用いてGoogleChromeを起動することができます。実際の認証突破コードは以下のようになります。
( 参考:https://chromedriver.chromium.org/capabilities#h.p_ID_64 )
from selenium import webdriver #Chromeオプションを設定 chrome_options = webdriver.ChromeOptions() chrome_options.add_argument("--no-sandbox") chrome_options.add_argument("--headless") chrome_options.add_argument("--single-process") chrome_options.add_argument("--disable-setuid-sandbox") #プロファイルが存在するディレクトリを指定 chrome_options.add_argument( "--profile-directory=/Profile 1") #プロファイルを指定 chrome_options.add_argument( "--user-data-dir=./chrome_profile") driver = webdriver.Chrome(options=chrome_options) driver.get( "https://google.com/")
CARUUPEにSeleniumでアクセスできるようなったら、全ページを取得していくプログラムを実行します。今回はホーム画面から深さ優先探索で全ページを取得するようにしました。
まず、ホーム画面から始めて、各ページのすべてのリンクをキューに追加します。その後、キューからリンクを取り出し、まだ訪れていない場合はそのページを訪れ、そのリンクをキューに追加します。これを繰り返すことで、すべてのページを訪れることができます。実際のプログラムは以下の通りです。
# Perform breadth-first search while queue: current_url = queue.popleft() url = f"https://sites.google.com{current_url}" page = get_page(url) pages.append(page) soup = BeautifulSoup(page.page_source, "html.parser") links = soup.find_all("a") for link in links: title = link.text children_url: Optional[str] = link.get("href") if title is None or children_url is None: continue if (children_url.startswith("http") or "caruupe" not in children_url): continue if (children_url in urls): continue try: child_page = get_page(f"https://sites.google.com{children_url}") except: print(f"Failed to get {children_url}") continue urls.add(children_url) queue.append(children_url) pages.append(child_page) if (len(pages) % 20): pagesDf = pl.DataFrame(pages) pagesDf = pagesDf.drop(["page_source"]) pagesDf.write_csv("pages.csv") with open("pages.pkl", "wb") as f: pickle.dump(pagesDf.to_pandas(), f)
取得したページからタイトル・ページテキスト、urlを抽出し、csvとして保存しておきます。 これを元にChatGPT(open AI Chat Completion API)に答えを生成してもらいます!!

ページテキストから質問に対する答えを作る
ここが今回の肝となります。スクレイピングによりCARUUPEの全ページテキストを保存することができたので、これから質問に対する答えをChatGPTに作ってもらいます!ChatGPTは優秀なので、例えば以下画像のように、 桃太郎の本文から質問に対する答えを探してくるように伝えると。

ちゃんと本文の情報を元に、質問に答えてくれます!!!
僕より天才ですね。


じゃあ取得したCARUUPEのページテキストくっつけて、質問と一緒にChatGPTに投げるだけで良さそうじゃん!!!!となるのですが、実際そんなうまい話はありません。OpenAIでは文章処理の基本単位として、トークンを用います。トークンは、文章や単語などのテキストの最小単位を指します。日本語では大体、1トークン=1文字となります。ChatGPTでは処理できるトークン数に制限があり、課金額もトークン数に比例します。それゆえ、CARUUPEの全ページテキストと一緒に質問をChatGPTに投げるのはそもそも文字数的に無理だったり、できたとしてもお金が一瞬で溶けます(泣)。
これを解決するには、質問と一緒に全ページのテキストを投げるのではなく、関連のあるページだけを投げるのが効率良さそうです。いわゆるRetrieval-Augmented Generation (RAG)というテクニックです。RAGは、検索と生成を組み合わせた手法で、まず関連する情報を検索し、その情報を元にテキストを生成します。簡単にいうと、質問内容から、CARUUPEのどのページに答えが載っていそうか?判断し、そのページを用いて答えを生成してもらいます。送る情報を、質問に関連する1ページに絞ることにより、トークン消費量を節約しながら回答を生成することが可能です。
流れとしては以下のようになります。
- ページテキストをベクトル化
- 質問内容をベクトル化
- 質問内容に最も類似しそうなページを検索
- 3の結果のページテキストと質問から、ChatGPTに答えを生成してもらう
1.ページテキストをベクトル化
ベクトル化は、文書の類似性を計算するための手法で、各文書を多次元空間上のベクトルとして表現します。簡単に言うと文章を数値にしてあげます。文書を数値にするとなんと文書同士の計算ができるようになります。これを元に文書で数学を適用することができます。
このベクトル化にはTF-IDFやWord2Vecなどの手法を使用できます。今回はOpenAIのEmbeddingAPIを用いて、スクレイピングで取得した全ページテキストをベクトル化しました。
ベクトル化した情報はcsvの列追加の形で保存しておきます。
以下は実際に使用したベクトル化関数です。こんな簡単にできちゃうのが便利ですね!!
def vectorize_openai(self, text: str, model: str = "text-embedding-3-small"): text = text.replace("\n", " ") return client.embeddings.create(input=[text], model=model).data[0].embedding
2.質問内容をベクトル化
ベクトル化したページテキストと質問の類似度を計算するため、質問もベクトル化する必要があります。こちらも同様に、OpenAI EmbeddingAPIを用いてベクトル化してあげます。
3.質問内容に最も類似しそうなページを検索
ページテキストと質問内容がベクトル化されているので、類似度を計算することができます。類似度の計算方法も色々考えることができます。例えば、「類似度=距離が近い」と解釈すると、最小の距離のものを「似ている」と見なすことができそうですね。
今回はよく使われるcos類似度を用います。cos類似度では2つのベクトルに対するcosを求め、方向が似ているかを見ます。cosの値が1なら、2つのベクトルは同方向となるので似てる。-1なら真逆の方向となるので、似てないといったように類似性を測れます。質問と全ページテキストとのcos類似度を計算し、最も値が大きかったページを、最も質問に関連するページとします。
実際のプログラムは以下の通りです。戻り値でページタイトル、ページurl、ページテキストを返却しています。
def matched_content_search(self,query:str): query_vector = self.vectorize_openai(query) cosine = np.array([self.calc_cosine(vector, query_vector) for vector in self.meta_df["vector"].values]) top_index = np.argmax(cosine) return self.meta_df.iloc[top_index][["title", "url", "content"]]
4.3の結果のページテキストと質問かに答えを生成してもらう
3のcos類似度で質問に関連するページが特定できたら、そのページのテキストと質問をOpenAIのChat CompletionAPIに入力し、答えを生成します。APIに渡すプロンプトを調整することも大事です。制約を課して思った通りに回答が生成されるよう、アトムが工夫してくれました。ありがとう!
実際のコードは以下です。answer関数にユーザからの質問(query)を入力することで、回答が生成されます。
def answer(self,query:str): top_df = self.search(query) title = top_df["title"] url = top_df["url"] content = top_df["content"] personality = """ あなたは、社内のポータルサイトの内容に関する質問に答えるヘルプボットです。次のガイドラインに従って回答してください。 ### ガイドライン - ポータルサイトの情報のみを参考にして回答してください。 - 利用者が求めている情報を明確に理解し、関連する内容を提供してください。 - 添付のURLは必ず出力例と同じ形式で出力してください。 ### 出力例 回答: 回答 URL: <URL|タイトル> """ input_text = f""" ### 質問 {self.query_text}\n\n ### 関連するポータルサイトの情報(タイトル、URL、内容) {title}\n{url}\n{content} """ response = client.chat.completions.create( model="gpt-4-turbo", messages=[ {"role": "system", "content": personality}, {"role": "user", "content": input_text}, ], ) return response.choices[0].message.content
感想
今回のOpenAIハッカソン研修を通して、特にこれから一緒に仕事をする同期たちと開発を行え、お互いのことを深く知れたのがとても良かったです!皆んなそれぞれ違うバッググラウンドを持ち、得意不得意も違う状態で、どうすれば目的を達成できるのか。誰が何を担当すれば効率よく開発が進むのか。学生時代での個人開発では見えなかった新たな視点を知ることができました。ここからはチームで開発することが増えるので、チームで付加価値をどう最大化していくか、をよく考えていけるようになりたいです。これからよろしくお願いします!!