



 CARTA Generative AI Lab所属のさかきー&やなぎです!
CARTA Generative AI Lab所属のさかきー&やなぎです!
今回、社内の課題を生成AIで解決する活動の一環として、様々なツールを利用してデータ分析に関する実験を行ったので、記事にして共有したいと思います!
1つの記事にまとめると内容が巨大になってしまうので、いくつかの記事に分けて紹介していきたいと思います。 本記事では、実験を行うに至ったモチベーションやどういった方に向けた記事なのか、これから紹介していく各ツールの概要などについて触れていきます。
目次
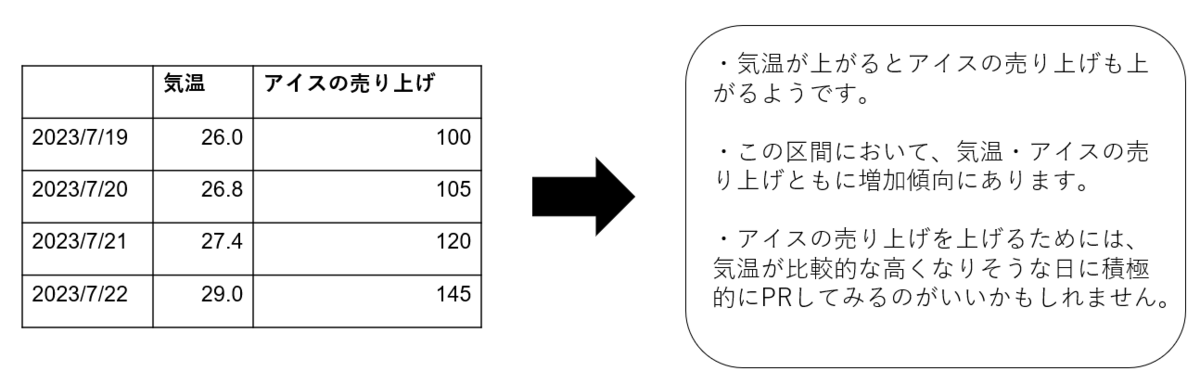
はじめに、本記事や本記事の関連記事をどういった方に読んでほしいのか、どんな方に向けた記事なのかを説明します。基本的には、以下のような方が想定読者です。 逆に、以下のような方は対象外かもしれません。 内容としては、ツールがどういったものなのか、実際に使ってみてどうだったのかを解説するものとなっています。 CARTA Generative AI Labとは、CARTA社内におけるAI活用とキャッチアップのためのチームです。 社内の課題やビジネスにおいて生成AIをどう活用できるか?ということや、次々に登場する生成AI関連技術をキャッチアップし、共有することを目的としています。 このような実験をするに至った経緯をお話しします。 一言で言えば、「データから得た情報を抽象化して考察する作業」を生成AIによって実現しよう、が実験モチベーションです。 CARTA Generative AI Labに期待されたタスクの1つとして、データ(主に多次元の時系列データ)を入力して、そのデータから傾向や考えられる仮説、改善点のようなものを文章で出力することが挙げられます。 例えば、以下のようなものです。 こういった作業は、一般的なアルゴリズムや機械学習モデルでは難しく、えてして時間がかかるものです。また、そのタスクの難易度の高さから現状は人の手で行っています。 そこで、「データから得た情報を抽象化して考察する作業」を生成AIによって手助けし、時間短縮や精度向上を図るタスクに私たちで取り掛かろう!となったのです。 まず、そもそもなぜこのタスクを生成AIを用いて行う必要があるかということについてお話します。 今話題としている"データから得た情報を抽象化して考察する"というタスクには、大きく分けて2つやるべきことがあります。 1. データを自動で処理し、基本的な統計情報や分析を行う 1は一般的なアルゴリズムでも解決できるような内容ではありますが、問題は2です。 現状、高い論理的思考能力を持ち、それをもとに自然言語文章を出力することができる最も一般的な手段は大規模な言語モデルだと考えられます。 しかし、一般的に言語モデルというものは外部データ等を厳密に利用できるようになっていません。 例えば、ChatGPTは、OpenAI社のヘルプで以下のように述べられています。 ChatGPT is not connected to the internet, and it can occasionally produce incorrect answers. It has limited knowledge of world and events after 2021 and may also occasionally produce harmful instructions or biased content. ChatGPT はインターネットに接続されていないため、不正確な応答が生成される場合があります。 2021 年以降の世界や出来事についての知識は限られており、場合によっては有害な指示や偏ったコンテンツを生成する可能性もあります。(Google翻訳) このように、少なくともChatGPTでは2021年以前の情報がデータセットとして学習に用いられているだけで、インターネットには接続されていません。そのため、デフォルトの状態では最新情報や追加の情報を扱う際にはその情報をテキストとして入力しなければいけません。 これは、他の多くの言語モデルにも当てはまることで、基本的には言語モデルが扱える情報は学習データに含まれているものに限られています。 また、言語モデルは構造上数値データ等の定量的なデータを厳密に扱えるようにはなっていません。昨今の言語モデルは論理的思考能力が飛躍的に進歩し、単純な計算や少量の数値データなら扱えるようにはなっていますが、確率的な処理が含まれる以上厳密とは言えません。 ではなぜこのような問題があるにもかかわらず生成AIを利用するに至ったのか。 それは、厳密にデータを利用しつつ、それを適切に出力文に反映することのできるツールが数多く登場してきているからです。 それに加えて、データ分析部分と考察文章生成部分をシームレスに接続するようなツールも多く登場してきています。 以上のような理由から、今回は生成AIを利用してこのタスクを解決していきます。 今回私たちが最終的に取り扱いたいデータは機密情報であり、精度の高さ・実装コストの低さ他に情報漏洩のリスクにも気を配る必要がありました。 よって、今回取り上げる予定であるツールにおける精度・実装コスト・情報漏洩リスクを評価した表を以下に示します。 なお、今回の一連の記事における情報漏洩リスクは、以下を総合的に鑑みて、どれか一つでも可能性があればリスクありと判断しています。 次々と新たな技術が出てくる昨今、すぐにもっと良いソリューションが出てくるかもしれませんので、これからも調査をしていきたいと思います。 詳細な方法は 想定読者
CARTA Generative AI Labの立ち位置
実験のモチベーション
手法と概要
2. 分析によって得られた結果を自然言語でまとめ出力する利用手法の精度・実装コスト・情報漏洩リスク
ツール名
精度
実装コスト
情報漏洩リスク
langchain Agent
〇
〇
〇
Pandas AI
△
〇
〇
Noteable
◎
◎
△
Advanced Data Analysis(旧Code Interpreter)
◎
◎
×
Code Interpreter API
〇
〇
〇
その2 から掲載していきます!