




まえがき
初めましてorお久しぶりです。K12SRこと鮠河です。
ニックネームを変更することになったのですが、この単語を聞いてピンときたアナタ。。。仲良くなれそうです。
さて、結局仕事の話になるのですが、以前書いた内容の続編的なことをしましたのでついでにブログも書こうという話になり筆を取りました。
前回内容のおさらい
まずは前回のブログの内容のおさらいからしたとおもいます。
前回はSendGridというメール配信サービスのアクティビティログをAWSのS3に保持するという内容を書きました。
そのときはS3に保持するだけて、今後の活用までまだ出来ていなかったのですが、今回はこのログを抽出してAWS Athenaで集計していきたいと思います。
S3の階層
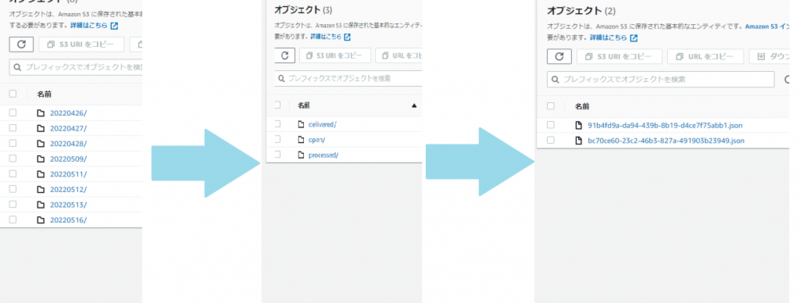
S3に保持されているアクティビティログの階層は日別毎にフォルダを作成し、その配下に各アクティビティタイプ(DeliveredやOpenなど)別にフォルダがありその下にログが置いてある状態です。
動作環境
今回はS3にあるログファイルをAWSのGlueでクローリングし、抽出したデータをAthenaで集計していきます。
動作完了は下記の通りです。
- AWS S3
- AWS Glue
- AWS Athena
Glueでクローラーの作成
まずはクローラを作成していきます。
AWSコンソールから「Glue」を選択します。そこから「クローラ」を選択し「クローラの追加」をクリック。
クローラの下記の様に設定を進めて来ます。
- クローラの情報
クローラの名前:任意(ここでは「test-crawler」 - クローラーソースタイプ
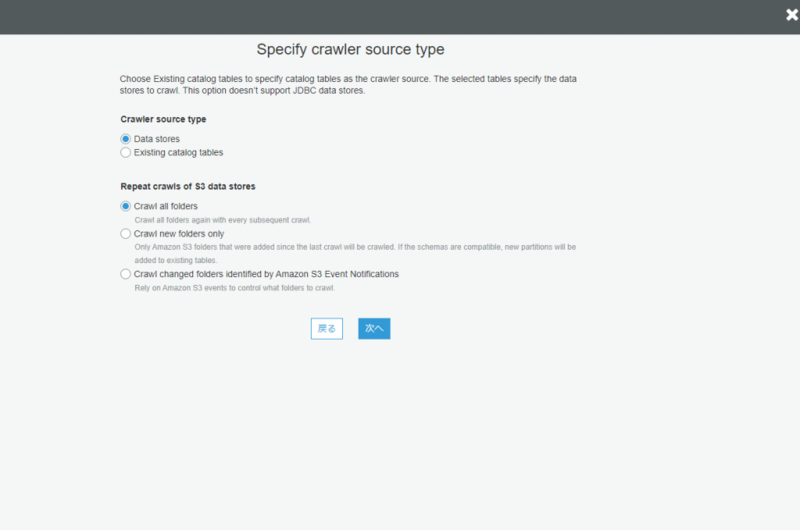
Crawler source type:Data stores
Repeat crawls of S3 data stores:Crawl all folders - データストア
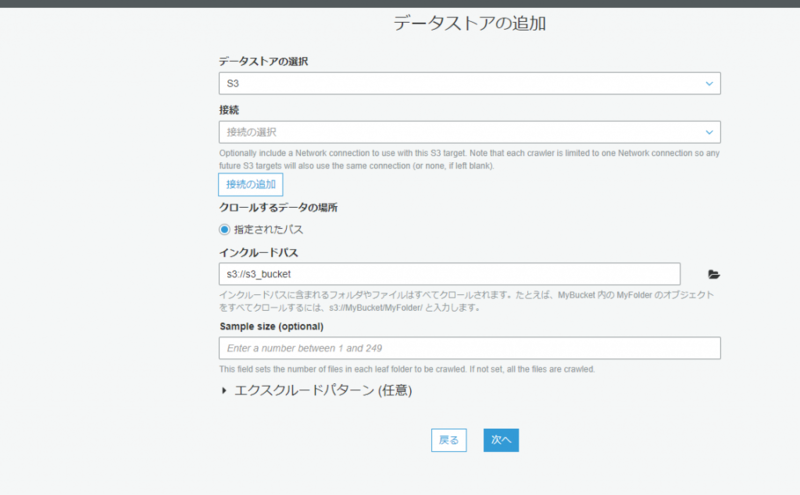
データストアの選択:S3
インクルードパス:S3のバケット(ここでは「s3://s3_bucket」)
別のデータストアの追加:いいえ - IAMロール
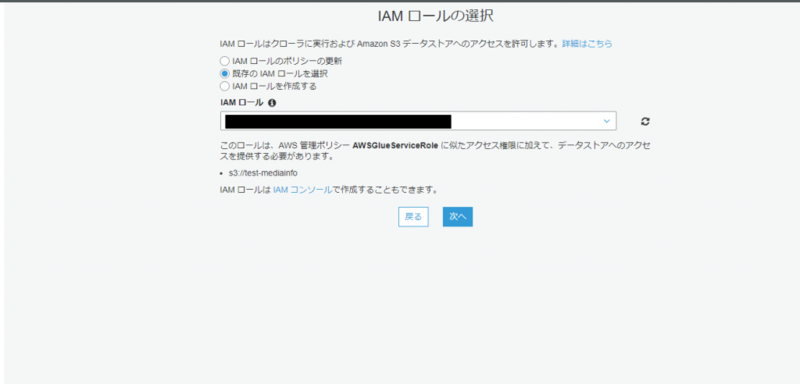
「既存の IAM ロールを選択」を選択
IAMロール:既存のIAMロールを選択(なければ新規作成して下さい) - スケジュール
頻度:オンデマンドで実行 - 出力
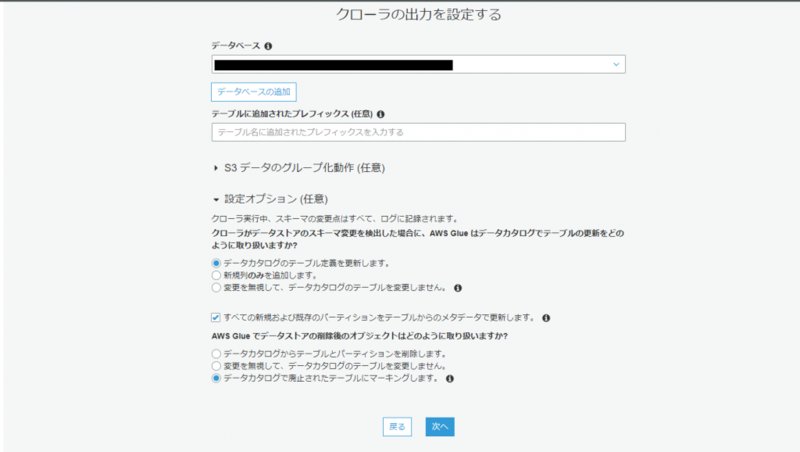
データベース:AWS Athenaで出力したいデータベースを選択
設定オプション(任意)の「すべての新規および既存のパーティションをテーブルからのメタデータで更新します。」にチェックを入れる
クローラの実行
クローラを作成すると一覧に表示されますので、早速実行していきます。
クローラの一覧画面から作成したクローラを選択して、「クローラの実行」をクリックし、あとは実行完了するまでしばらく待ちます。
完了するとログのリンクが表示されるのでログを確認し、エラーなどないか確認します。問題がなければクローラの作成・実行は完了です。
Athenaで確認してみる
早速AWS Athenaで作成されたデータを確認していきます。
コンソールから「AWS Athena」のサービスへ遷移し、クローラで選択したデータベースを選択します。
テーブルの一覧からクローラと同じテーブル名があればとりあえず問題ないと思うので表示してみます。
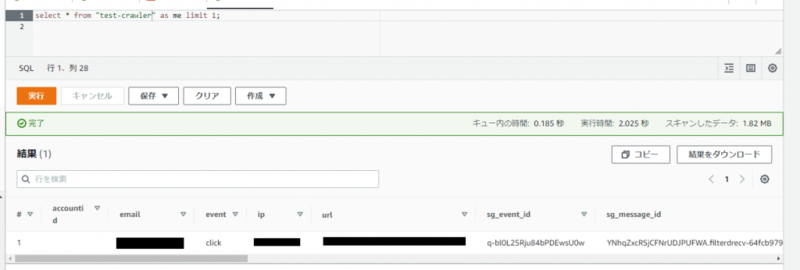
あとはメールアドレス毎にまとめるとか、イベント毎にまとめるとか色々出来ると思います。
まとめ
今回はクローラを使ってログを集計・抽出してみました。
クローラの作成もおもったより簡単だったので、いろんなログを抽出してデータ分析してみたいですね。
とりあえず今回はここまでにしたいと思います。それではまた逢う日まで~!