




はじめに
こんにちは、CCIのくっちーです。
広告資料管理のプロダクトを開発しています。
今回はMongoDBのインデックスを見直して、パフォーマンス改善したことについて書こうと思います。
前提条件
- MongoDBのバージョン:6.0
- ストレージエンジン:WiredTiger
- 環境:AWS
- 構成
- レプリカセット:3つ
- シャードは使っていない
この記事について
書いてあること
- MongoDBのインデックスを見直したこと
- クエリに適したインデックスを追加し、aggregationクエリの速度改善
- 単一インデックス、複合インデックスの作成戦略
書いていないこと
- 改善対応後のAPIパフォーマンス計測について
- AWS X-Rayを導入し計測、こちらの説明は割愛
- 業務で取り組んでいないこと
- シャード構成でのパフォーマンス改善
- インデックスの仕組み
- insert・update・deleteクエリについて
- クエリのパフォーマンスチューニング
- 改善対応後のAPIパフォーマンス計測について
インデックスを見直すきっかけ
ユーザーから画面表示が遅いと問い合わせがあったことです。
当時は画面表示に約10秒ぐらいかかっていました。
パフォーマンス劣化の調査方法
ChromeのDeveloperツールで遅いAPIを特定し、ログでMongoDBを確認する流れで進めました。
調査した結果、MongoDBのaggregationクエリがボトルネックになっていることが分かりました。
遅いクエリのログを確認するとインデックスが適切に使われていなかったため、インデックスを見直すことにしました。
公式ドキュメントにも、インデックスがあると読み取り処理の効率が良くなると書いてあります。
【参考:公式ドキュメント クエリ パフォーマンスの最適化 】
www.mongodb.com
インデックス見直しの進め方
以下の手順で進めていきました。
- メモリに乗っているインデックス容量を確認
- 現状インデックスが使われているか確認
- 2で適切なインデックスでは無かった場合、インデックスを作成
- 作成後、インデックスが使われているか確認
メモリに乗っているインデックス容量を確認
インデックスはメモリに乗せるとパフォーマンスが向上するので、メモリに乗っているインデックスの容量が重要になります。
上記は公式ドキュメントのインデックス戦略の中に書いてありました。
【参考:公式ドキュメント インデックスをRAMに確実に収める】
https://www.mongodb.com/ja-jp/docs/v6.0/tutorial/ensure-indexes-fit-ram/www.mongodb.com
インデックスの量は制限があるため、作成前に以下を確認しておきます。
- インデックスの合計サイズの上限
- 作成済みインデックスの合計サイズ
この2つからインデックスを新規作成する余裕があるか判断します。
MongoDBのインデックスの合計サイズの制限
合計サイズの制限は特に設けられていません。
しかし、容量が大きくなるとパフォーマンスが低下するので闇雲に作成するのは良くないです。
ここからはパフォーマンスが低下しないインデックスサイズの上限の算出方法について書いていきます。
公式ドキュメントによると、MongoDBに割り当てられるメモリは物理サーバーの50%となっています。
【参考: 公式ドキュメント WiredTiger ストレージ エンジン > メモリの使用】
www.mongodb.com
メモリ使用率が80%を超えると、利用頻度の低いワーキングセットが解放されるようになっています。
この時にディスクI/Oが頻繁に発生し、パフォーマンスが低下するので使用率は80%以下に抑える必要があります。
【参考:MongoDB Developer Community 「Question regarding large transaction and limited WiredTiger cache size」】
www.mongodb.com
推定される利用可能なインデックスサイズは以下の式で算出できます。
物理サーバーの容量 × MongoDBへ割り当てられる割合(50%)× インデックスが利用可能なメモリ使用率(80%)
担当プロダクトの場合、物理メモリは16GBなので約6.4GBがインデックスの合計サイズの上限と推定されます。
16×0.5×0.8=6.4
MongoDBのメモリにはインデックス以外も使うので、実際に割り当てられる容量は更に少ないと思います。
作成前のインデックスの合計サイズ
db.stats()メソッドを実行し、indexSizeを確認します。
担当プロダクトは3.24GBでした。
理論上の上限まで約3.16GBの余裕があるので作成可能と判断しました。
作成するインデックスを決める
今回は読み取り処理の改善のため、対象クエリで適切なインデックスが使われているか確認します。
まずはどのインデックスが使われているか確認します。
公式ドキュメントのインデックス戦略を参考にし、適切なインデックスが使われているか調査していきます。
【参考:MongoDB 公式ドキュメント】
www.mongodb.com
使われているインデックスを確認
公式ドキュメントによると、explain()メソッドでクエリのパフォーマンス分析が可能になっています。
クエリの末尾にexplain()を追加すると実行結果が出力されます。
【参考:MongoDB 公式ドキュメント】
www.mongodb.com
実行結果のqueryPlanner.winningPlan.inputStage.stageに、インデックスが使われているか出力されています。 以下は出力結果から一部抜粋しています。
explainVersion: '1', queryPlanner: { //...省略... maxIndexedOrSolutionsReached: false, maxIndexedAndSolutionsReached: false, maxScansToExplodeReached: false, winningPlan: { stage: 'FETCH', inputStage: { stage: 'IXSCAN', // インデックスを使っているか keyPattern: { fileName: 1 }, indexName: 'fileName', // 使っているインデックス isMultiKey: false, // 複合インデックスか //...省略...
queryPlanner.winningPlan.inputStage.stageの値は以下になることが多いです。
- COLLSCAN:ドキュメントをフルスキャンしておりインデックスが使われていない
- IXSCAN:インデックスを使って効率良くドキュメントを読みこんでいる
他のものは公式ドキュメントにあります。
[参考: 公式ドキュメント explain の結果 > インデックスの交差]
https://www.mongodb.com/ja-jp/docs/v6.0/reference/explain-results/#index-intersection
IXSCANの場合、ESR (等価、並べ替え、範囲)ルールに沿ったインデックスが使われているか確認します。
公式ドキュメントによると、ESRを適用すると効率的な複合インデックスを作成できるそうです。
【参考:MongoDB 公式ドキュメント】
www.mongodb.com
例えば下記のクエリの場合、disabled,fileName,fileIdの複合インデックスが必要になります。
db.file.aggregate([ {$match:{$expr:{$and:[{$eq:[$fileName,"blog"]},{$ne: [$disabled, true] },]}}}, { $sort : { fileId: 1 }}, { $lookup: { ...省略...
もし他のインデックスが使われていた場合、新たに作成するとパフォーマンスが改善することが多いです。
作成したインデックス
パフォーマンスが低下していたクエリはインデックスが使われていない、もしくは適切なインデックスではなかったため新規作成しました。
新規作成のインデックスサイズは予測できないので、最低限の件数にしています。
今回は実行時間が1秒以上のクエリのみを対象にして、4件作成しました。
作成後のインデックス合計サイズ
作成後のインデックスサイズは3.5GBでした。
上限は6.4GBなので、今後データ量が増えても問題なさそうです。
つまずいたところ
検索条件にあったインデックスを作成しても、パフォーマンスが改善されないことがありました。
explainコマンドで確認すると、作成したインデックスが使われていないことが分かりました。
$matchが複数ある 場合、適切なインデックスが使われない!!
$matchが複数ある場合、先頭の$matchに一致するインデックスしか使われないことが原因でした。
Webアプリでは動的クエリを実装していたため、検索条件が増えると$matchが追加されるようになっていました。
// 以下のクエリでは、disabledインデックスが使われていた // 適切なインデックス は disabled,fileName,fileIdの複合インデックス db.file.aggregate([ {$match:{disabled:{$ne:true}}}, {$match:$expr:{$and:[{$eq:[$fileName,"blog"]}]}}}, { $sort : { fileId: 1 } }, { $lookup: { ) ...省略...
公式ドキュメントにも「1 つ のインデックスしか使用しません」と書いてありました。
【参考:公式ドキュメント インデックスの作成に関する戦略】 www.mongodb.com
explainでIXSCANのインデックスを確認すると、先頭の$matchで指定したフィールドのインデックスが使われていました。
解決方法
$matchを結合すると適切なインデックスが使われるようになり解決されました。
explainコマンドでもインデックスが使われていることが確認出来ました。
// インデックス : disabled,fileName,fileIdの複合インデックス db.file.aggregate([ {$match:$expr:{$and:[{$eq:[$fileName,"blog"]},{disabled:{$ne:true}}]}}}, { $sort : { fileId: 1 } }, { $lookup: { ) ...省略...
結果
APIのパフォーマンスが向上し最大で約6秒速くなりました。
画面表示も10秒から2秒ぐらいに改善されたので、ユーザーからパフォーマンスの向上を評価する声をいただきました。

今後の展望
今後もパフォーマンスが低下する可能性があるので、AWS X-Rayを導入し計測することにしました。
朝会でAWS X-Rayのダッシュボードを確認する時間を設けています。
実行時間が遅い順に並んでいるので、どのAPIが遅いか、急激に悪化していないかを見ています。
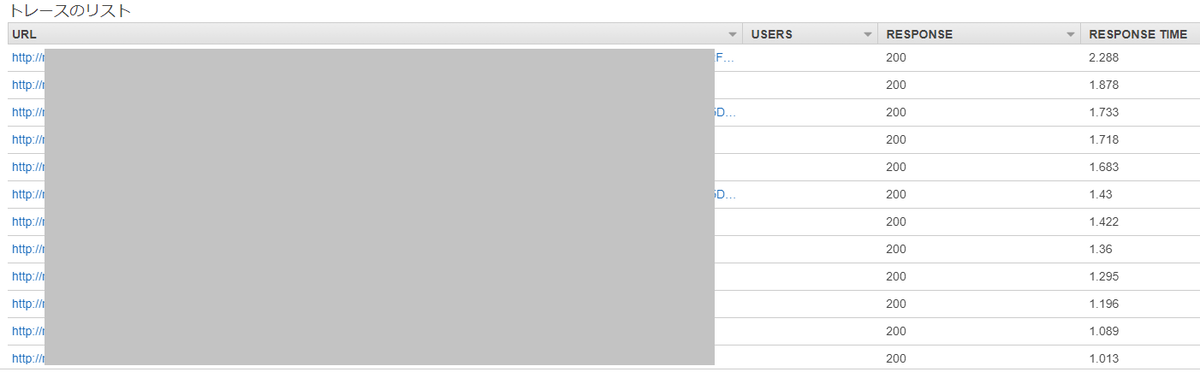
今回対応したAPIはパフォーマンスを維持出来ているので、現状は問題無さそうです。
しかし、他にもパフォーマンスが悪いAPIがあるので引き続き対応が必要そうです。
これからもシステムの内部状況を把握し、パフォーマンス改善を進めていきたいと思います。