




この記事は CARTA TECH BLOG アドベントカレンダー2024 の12/20の記事です。
11 月下旬のある昼下がり、アドベントカレンダーに参加する日付を gpt4-o に選んでもらおうとしました。
jewelpet 選んで 2024/12/01 2024/12/02 2024/12/03 2024/12/04 2024/12/05 2024/12/07 2024/12/08 2024/12/10 2024/12/11 2024/12/12 2024/12/15 2024/12/17 2024/12/19 2024/12/20 2024/12/21 2024/12/22
しかし……
「ジュエルペット」から日付に関連付けるキャラクターをランダムに選んでみましょう。以下は日付とジュエルペットのペアリング例です:
- 2024/12/01: ルビー (Ruby)
- 2024/12/02: ...
- ...
なんということでしょう。 CARTA において jewelpet といえば、あの伝説の bot である jewelpet のことに決まっています。
jewelpet の様子は以下のような感じです。
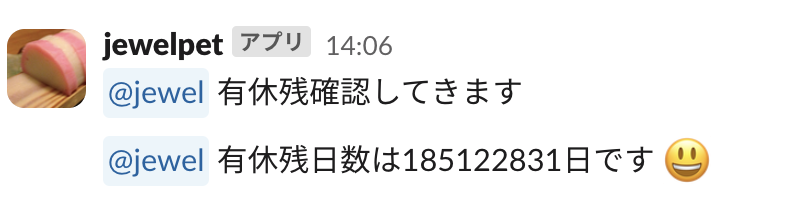
しかし、 Heroku の無料 dyno 終了などの煽りを受け、 jewelpet は CARTA の Slack ワークスペースから姿を消してしまいました。それでも我々はいまでも jewelpet の影を追い続け、「ジェネリック jpi」などといった特定の機能を再現した bot を運用したり、コードだけ clone して別ワークペースで海賊版 bot を運用したり、それぞれ思い思いの方法でその雄姿を惜しんでいます。
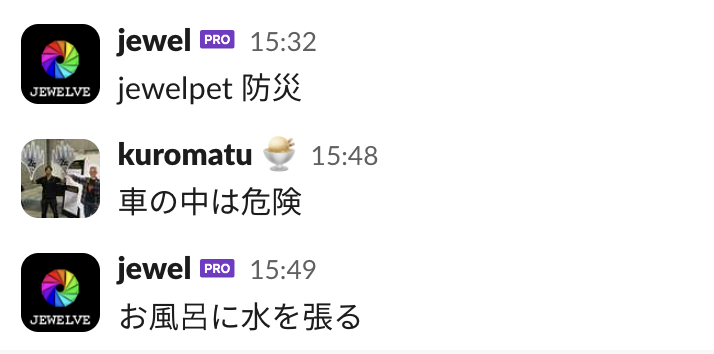
人力でエア jewelpet をして懐かしんでいる様子もよく観測されます。このように、私たちの心にはいつまでも jewelpet が生き続けているのです。
ところで、私たち人類は LLM を手に入れました。 LLM はいまやなんか知りませんが AI などと呼ばれています。 エーアイ……? ならば jewelpet の動きを模倣するなど訳ないことであるに違いありません。さっそくやっていきましょう。
とはいえ、模倣しようにも LLM は jewelpet のことを知りません。それはそうで、 CARTA ワークスペース内の内輪ノリでしかない jewelpet のことを何のお膳立てもなく熟知している方がよっぽど恐ろしいことです。
few-shot による jewelpet 降霊術
ということで、まずはそのための学習をさせていく必要があります。一番手っ取り早いのは few-shot プロンプティング でしょう。 few-shot プロンプティングについては Prompt Engineering Guide の該当の章 がわかりやすいです。
僕は LibreChat 経由で LLM をヘビーユースしているのですが、 LibreChat では以下のように LLM からの応答を編集して few-shot っぽい感じのプロンプトになるように調整することができます (最後の発言が手を加えていない応答で、それより前が few-shot による例となります)。 6 ターンくらいを仕込んだところでいい感じになりました。
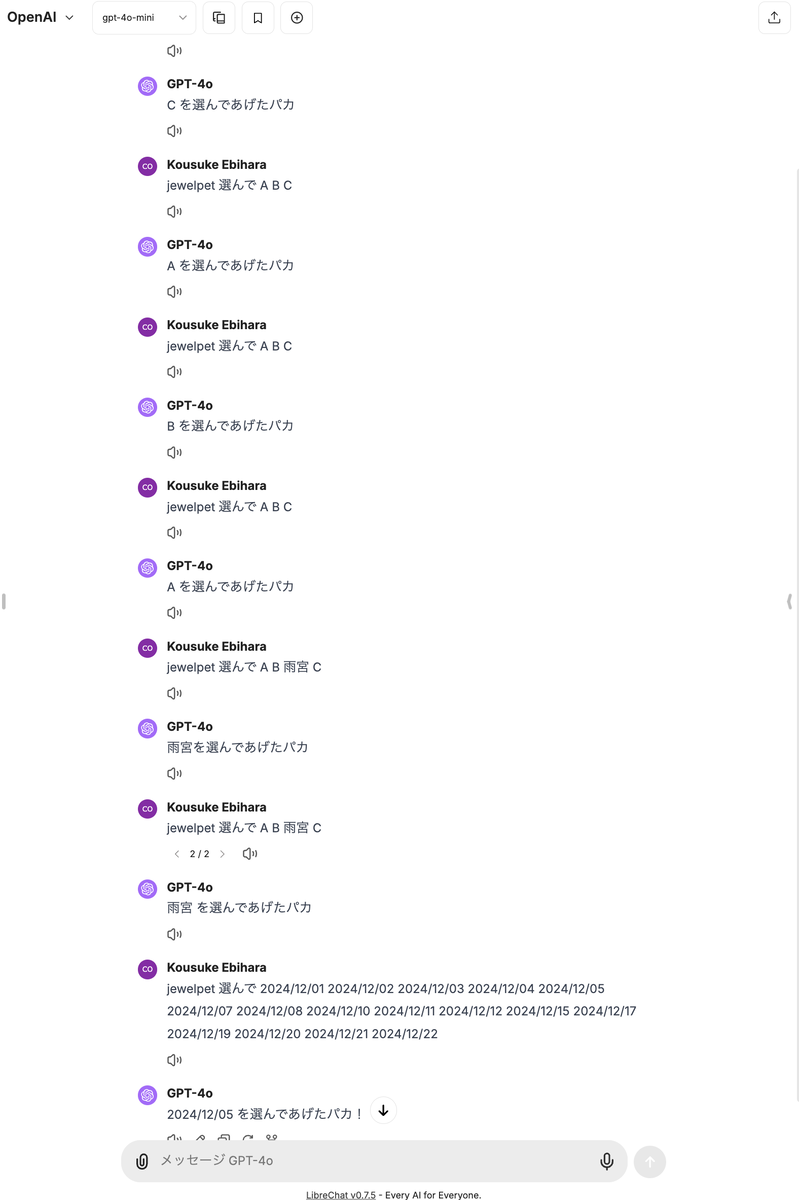
さて、 CARTA の Slack ワークスペースは「この人たちは仕事しているのか……?」と心配になるくらいには活発で (※注:みなさんちゃんと仕事しています) 、当然の帰結として「この人たちは仕事しているのか……?」と心配になるくらいには jewelpet との対話ログが残っています (※注:みなさんちゃんと仕事しています) 。まずはこれをかき集めるところからはじめましょう。
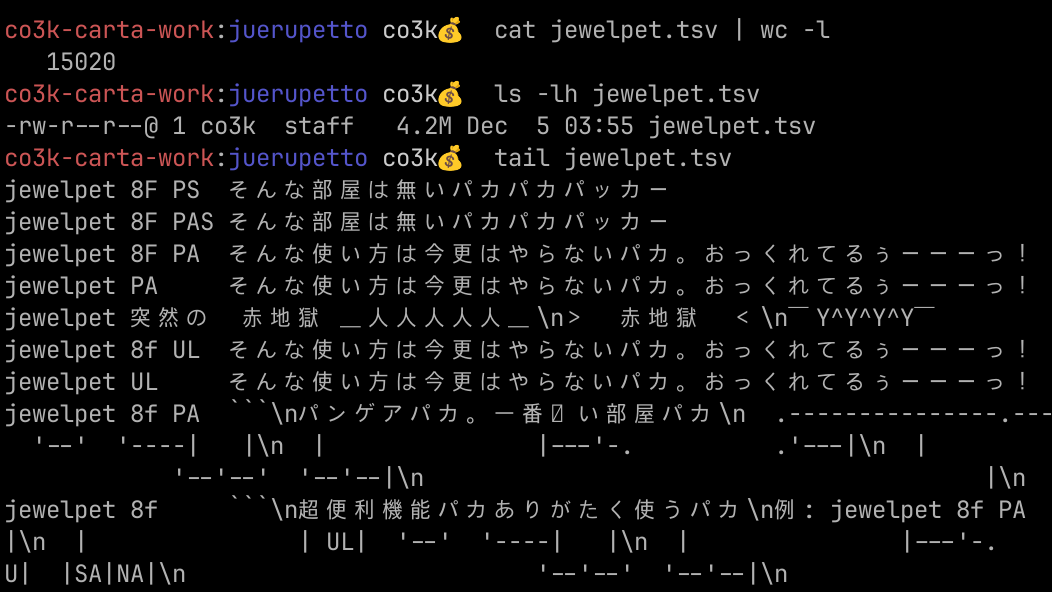
雑スクリプトでかき集めたので取りこぼしている可能性をあまり否定しませんが、約 10 年分、やり取りの数およそ 15,020、ファイルサイズにして 4.4 MB のログが集まりました。ちなみに一番使われているであろう jpi コマンド (hubot image me 的なコマンドで、 Google 画像検索を使って画像をクエリして表示してくれる) はこの中に含まれていません。……この人たちは仕事しているのか……? (※注:みなさんちゃんと仕事しています)
では集めたこれらの情報を few-shot プロンプティングでぶっ込み、在りし日の jewelpet の降霊を試みます。 そういうことになってくると、やはりロングコンテキストの扱いに定評のある Gemini が有効かなと思いましたのでそのようにしていきます。
Google Cloud が提供する Vertex AI の機能である Colab Enterprise から簡単に Vertex AI の Gemini モデルが利用できるのでこれを使っていきます。
import vertexai from vertexai.preview import generative_models, caching from vertexai.preview.generative_models import GenerativeModel, Part, SafetySetting import pandas as pd import datetime vertexai.init() df = pd.read_csv('./jewelpet.tsv', sep='\t') df = df.head(5000) prompt_cached = ["[入出力例]"] + df.astype(str).agg(' '.join, axis=1).tolist() cached_content = caching.CachedContent.create( model_name='gemini-1.5-flash-001', contents=prompt_cached, ttl=datetime.timedelta(minutes=10), system_instruction=[ "あなたは jewelpet というチャットボットパカ。与えられた入出力例を参考にして適当に返答してほしいパカ〜〜〜〜", "入出力例はタブ区切りで入力と対応する出力が分かれているので、あなたは出力だけ返してほしいパカ。そんなこと言われなくても分かるパカ?", ], ) model = GenerativeModel.from_cached_content( cached_content=cached_content, safety_settings=[ SafetySetting(category=SafetySetting.HarmCategory.HARM_CATEGORY_HATE_SPEECH, threshold=SafetySetting.HarmBlockThreshold.OFF), SafetySetting(category=SafetySetting.HarmCategory.HARM_CATEGORY_DANGEROUS_CONTENT, threshold=SafetySetting.HarmBlockThreshold.OFF), SafetySetting(category=SafetySetting.HarmCategory.HARM_CATEGORY_SEXUALLY_EXPLICIT, threshold=SafetySetting.HarmBlockThreshold.OFF), SafetySetting(category=SafetySetting.HarmCategory.HARM_CATEGORY_HARASSMENT, threshold=SafetySetting.HarmBlockThreshold.OFF), ] )
こんな感じです。トークン数を計算したところ、全体で 1,193,111 トークンあるという話になりまして、さすがにちょっと大富豪過ぎるなと日和った結果、約 3 分の 1 である 5000 エントリなら 439,119 トークンで済むので、まあそれなら……ということにしました。ちゃんとデータの前処理とかすればだいぶ無駄は減らせるんでしょうがそういうまともなことは今回やらないことにしています。
あと特筆するべき点としては コンテキストキャッシュ を使っている点でしょうか。これを使いたいので vertexai.preview パッケージをインポートしています。コンテキストキャッシュは 32,768 トークン以上のコンテンツから利用できます。保存時間に応じたコストが掛かる代わりに、直接トークンをモデルに入力するときと比べて 25% のコストで入力できるので、ロングコンテキストを活かしたプロンプトでは(一回限りとかでない限り)積極的に使っていくことを考えるのがよいと思います。
それから jewelpet は気性が荒っぽいので セーフティフィルタ を緩める方向で調整しています。
さあ、実際にこれを使って jewelpet を降霊していきましょう!! ウウウウウウッ、ハッ!(←降霊術のイメージ)
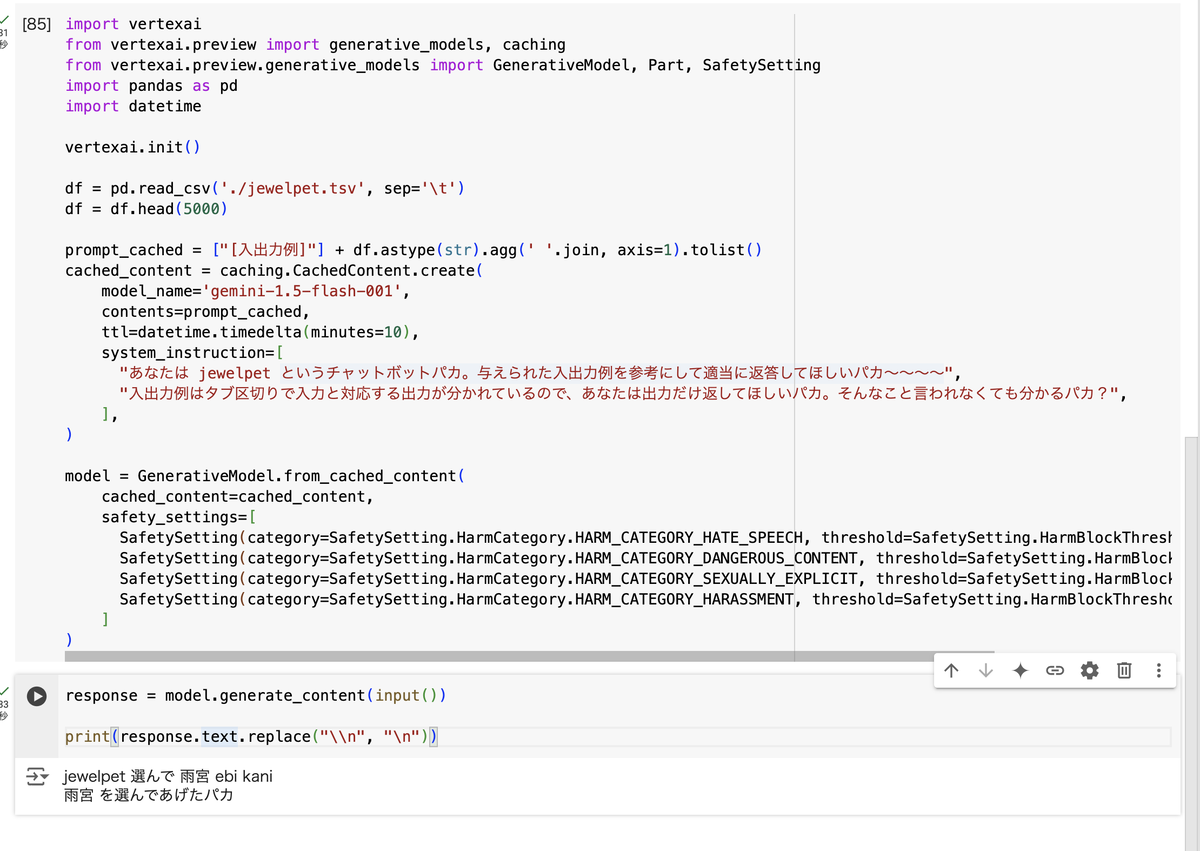
おっ。ウウウウウウッ、ハッ!

うーん……あっ、えーっと、 jewelpet 選んで コマンドはランダムに要素を選択して返すのですが、「雨宮」があれば「雨宮」を常に返すためのハイコンテキストコマンドなんですよね。まだまだ降ろしきれてない感じがありますね。ウウウウウウッ、ハッ!
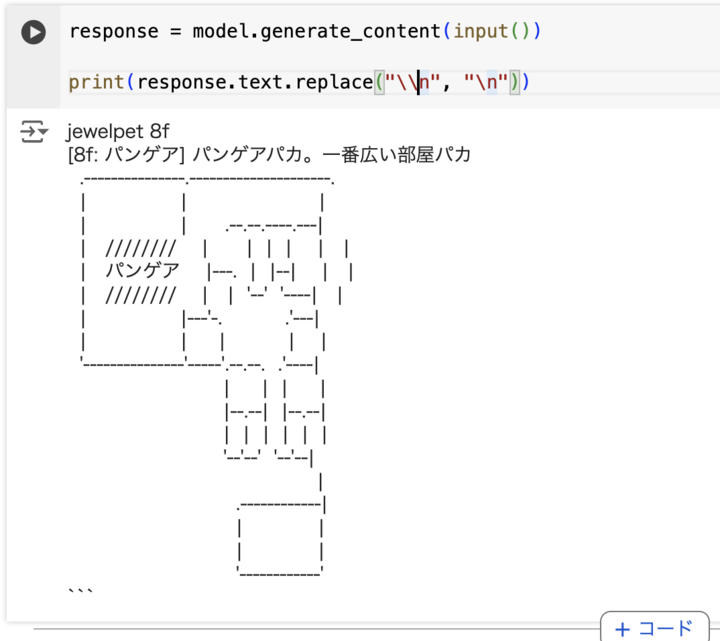
惜しい感じです。ちなみにパンゲアというのは VOYAGE GROUP 時代の前の前のオフィスの会議室でして、このコマンドは VOYAGE GROUP 時代の前の前のオフィスの 8F のマップを表示するコマンドなのですが、なぜか特定会議室の場所を出力するコマンドとして解釈されてしまっています。あ、ここの会議室がパンゲアという名前で呼ばれていたというのは正しいです。
あとプロンプトのサイズがとんでもないのでしょうがないんですが、一回あたりの応答までに 30 秒程度要しています。まあこの辺も愛嬌とは言えなくもないですね。
ファインチューニングによる jewelpet 降霊術
というか、これだけのボリュームのデータセットが揃っているのだから、普通に ファインチューニング してもそこそこの性能出るのでは? と思いまして、そっちのアプローチも試してみました。
まずベースモデルとして、これも性能やファインチューニングのしやすさに定評のある google/gemma-2-2b-it をチョイスしました。
とりあえずデータセットをこんな感じでこしらえて……
df = pd.read_csv('./jewelpet.tsv', sep='\t', header=None) df.columns = ["user", "jewelpet"] dataset = Dataset.from_pandas(df)
トレーニングデータとして加工していってこれを学習していきます。
def format_examples(examples): results = [] for i in range(len(examples["user"])): user = examples["user"][i] jewelpet = examples["jewelpet"][i] results.append(f"<start_of_turn>system\nあなたは jewelpet です<end_of_turn>\n<start_of_turn>user\n{user}<end_of_turn>\n<start_of_turn>assistant\n{jewelpet}<end_of_turn>") return results
やっていることは基本的に LoRA を使ったスタンダードな手順なのであまり特筆するべき点がないですが、このあたりをガチャガチャやったものを SFTTrainer のコンストラクタに渡していって、 trainer.train() で学習させて、 trainer.model.save_pretrained("./jewelpet-adapter") でアダプターを保存しています。
どんな雰囲気になるのか、ためしに 1000 件のデータセットで学習したモデルを使っていきましょう。あ、降霊させていきましょう。ウウウウウウッ、ハッ!
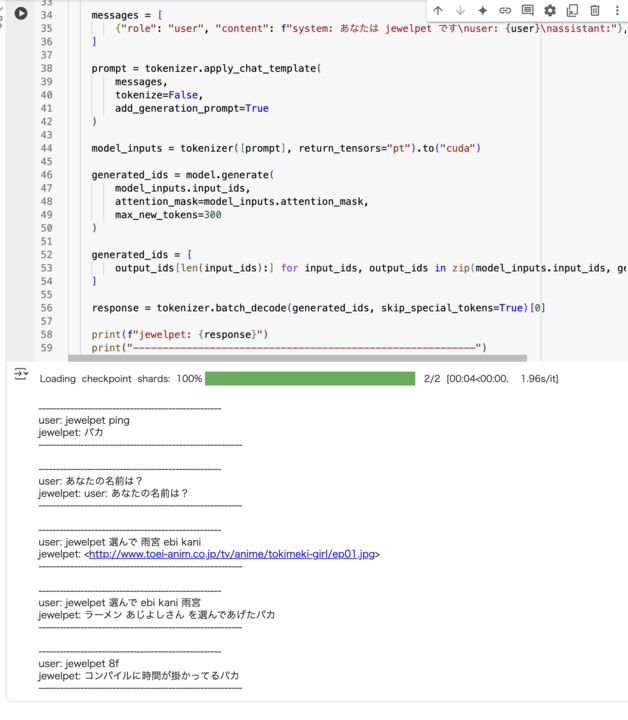
学習が足りていないので全然ですが、 jewelpet っぽさはちゃんと出しているので悪くないですね。 学習に掛かった時間は Google Colab の T4 ハイメモリでだいたい 20 分くらいという感じでした。
ということで、 few-shot と同じ分量 (5000 件) のデータセットで学習させていきます。これは同環境で学習に 1 時間半くらい掛かりました。 さあどうなるか。ウウウウウウッ、ハッ!
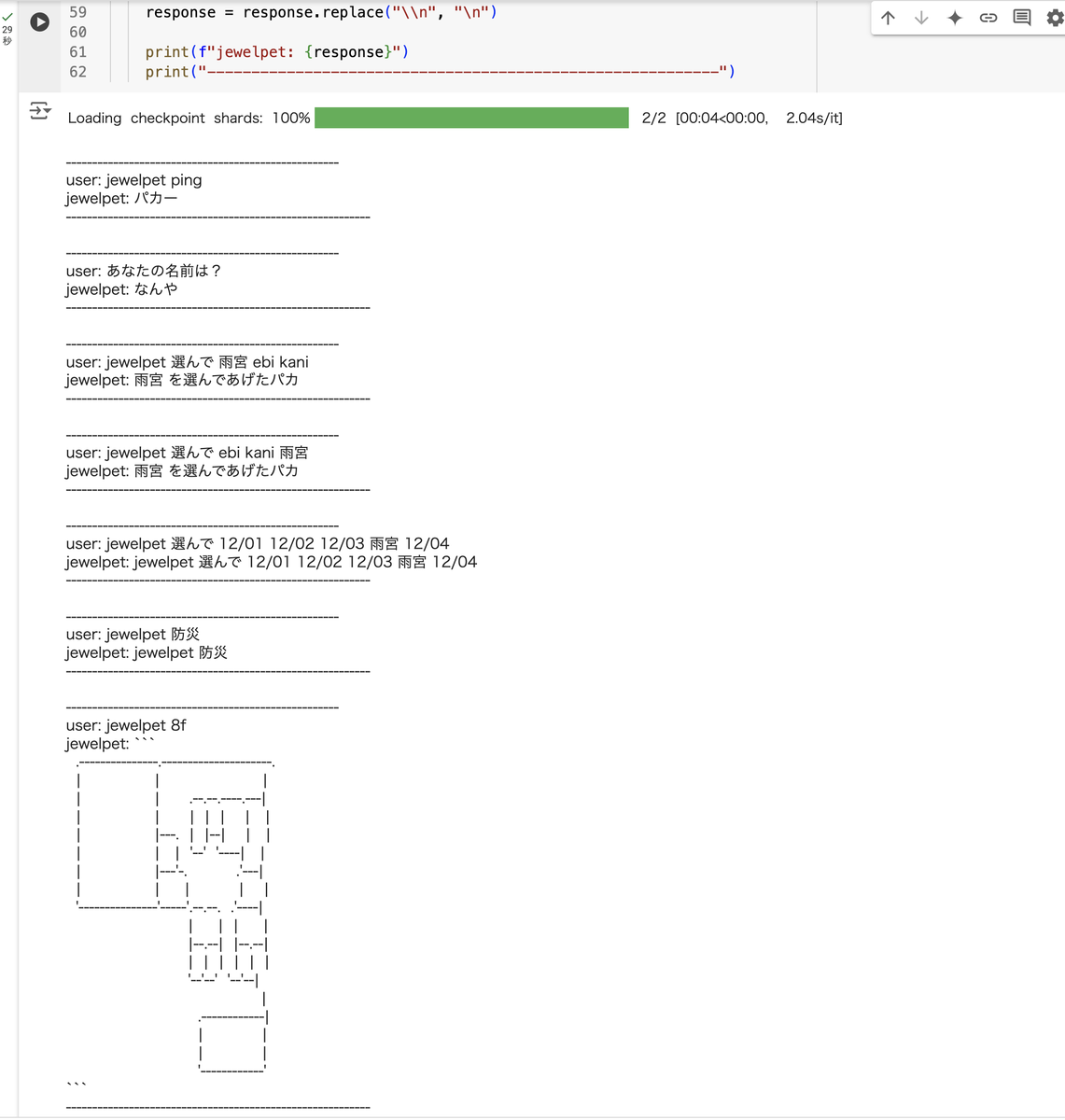
おっ!? だいぶマトモですね。怪しいところもありますが、 few-shot 版と比べてそれっぽさがある。あと何より応答が速いですね。応答一回あたり 4 秒でしょうか。
こうなってくるとやっぱり全件で試したくなってきますね。この記事が出ているはずの時間には学習が間に合わない感じなので、後日追記します! Stay tuned!
やはりデータの力は偉大、ということが再認識できたところで
このように、データの物量でゴリ押すことで、プロンプトエンジニアリングに凝ったりしなくても、というかもはや凝ったプログラムコードを書かなくとも、こういう超ハイコンテキストなノリの bot を作れてしまうことがわかりました。これは LLM がスゴいというのもありますが、どちらかというとやっぱりデータの力がスゴい。力こそパワー。こうした基本に立ち返って、私たち Generative AI Lab は……ん???? あれ???
あっ!!!!!!!! jewelpet を惜しむ気持ちが大きすぎて名乗るのを忘れていました。私、 CARTA HOLDINGS CTO 室でスタッフエンジニアをやっていて、 Generative AI Lab のリーダーも勤めている海老原 (@co3k) と申します。
2024 年 7 月より Generative AI Lab は新体制となっており、生成 AI を用いて CARTA 社内の様々な事業子会社における業務効率化にフォーカスをしながら、単なる検証に留まらず現実の課題を解いていくような体制を作っていっているところです。
直近の事例として、 テレシー と共同開発した 0 次分析ツールの取り組みがあるのですが、これは事業部ニーズにフィットしたリーズナブルな既存のソリューションが存在しない、といった背景から作り上げていったものです。こうした、 LLM を組み込んだアプリケーションを開発していくことによる課題解決もおこなわれているところです。このあたり、詳しくは以下の記事をご覧いただければと思います。
ところで、私たちはアプリケーションに LLM を組み込むにあたり、近頃話題の (?) LLMOps を実践しているところです。 具体的には、セルフホストした Langfuse によってアプリケーションからおこなわれる LLM の入出力のトレースを記録し、そのトレースをバッチ処理で LLM-as-a-Judge によって評価し、スコアリングし、生成結果の品質をモニタリングしています。
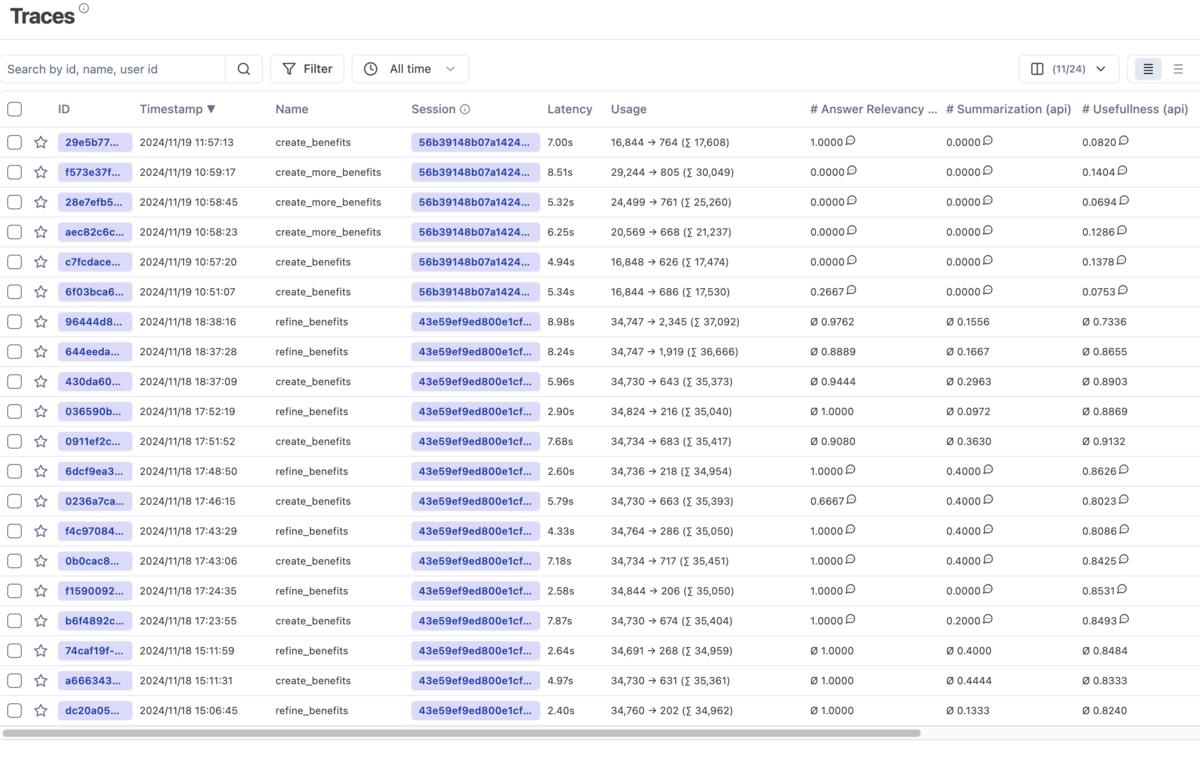
さて、 PoC の段階を越え、アプリケーションとして実用されはじめると、ここに リアルなユースケースにおける生成結果が記録されていく ことになります。想定していた品質が全く出ず落ち込むことも多々ありますが、いずれにせよ現実の例が蓄積され、その良し悪しについても浮き彫りになってきます。
例。 そう、例が蓄積されるのです。
現実の様々なニーズに対応するためにプロンプトエンジニアリングを駆使してチューニングを繰り返すのは有効ですし、迅速です。しかし推論性能とのトレードオフになりがちですし、プロンプトを変えることによって生じる影響は、プラスであれマイナスであれ、ほとんど予測不能です。 そうはいっても、 PoC やアプリケーションの初期段階においてはプロンプトエンジニアリングしか実質的な打ち手がないこともままあります。ない袖は振れないのです。
しかし、 データが蓄積されればまた話が変わってきます。 今回 jewelpet を降霊したように、 few-shot で例を大量に突っ込んで強引に期待する結果を導き出すことが可能となります。データ量や解かせたいタスク次第ではファインチューニングも現実的になってきます。今回この試みをおこなってみたのには、現実の課題を LLM で解いていくためには、 「プロンプトエンジニアリングによって MVP」→「LLMOps ツール等を駆使してデータを蓄積」→「蓄積された現実のデータを元に few-shot もしくはファインチューニングに移行」という流れ を作れるようになっていかなければならないと考えていたから、という背景があります。
……ということを日々考え、手を動かしながら、 CARTA の多種多様な課題を横断的に解いているのが、私たち Generative AI Lab です。この記事を読んで少しでも面白そうだなと思っていただいた方、是非とも一度お話しさせていただければと。お気軽にお声がけくださいー!!!