



こんにちは。fluctでiOS/Android向けSDKの開発をしているarimuraです。この記事ではPhilip Fisher-Ogden、Greg Burrell、Dianne MarshによるFull Cycle Developers at Netflix — Operate What You Buildを私が翻訳したものを著者の許可のもとに掲載しています。元の記事は弊社の技術力評価会のインプットの一つとして共有されており、そこで興味を持ったのが翻訳するきっかけとなりました。
以下、2018年5月時点における情報を記載したものであり Netflix TechBlog「Full Cycle Developers at Netflix」より引用したものである。
Netflixにおけるフルサイクル開発者―開発したものが運用する
2012年―Netflixでの重要なサービスの運用は骨の折れるものだった。デプロイは湿った砂の上を歩くように感じられた。カナリアリリースは機能ではなく忍耐力を検証するものとなっていた(「1週間何も壊れなかったからプッシュしよう!」)。問題の調査はチーム間でゴムボールを弾ませているようだし、原因の解明は難しく、次々と跳ね返ってくるボールを止めるのはさらに難しかった。これらの全ては変化が必要なサインだった。
そして2018年。Netflixは世界中の会員1億2500万人が1日に1億4000万以上の時間を楽しむまでのサービスに成長した。私たちはエンジニアリングチームの開発と運用の改善のために莫大な投資を行った。サービスの開発と運用を様々なアプローチで試した。その中からNetflixでよく使われているあるアプローチを、その良い点と悪い点を含め紹介したい。私たちの試みを共有することでそこから議論が発展し、何かを学んでもらえれば幸いだ。
1つのチームでの旅
エッジエンジニアリングのチームはNetflixのストリーミングを動かすためのAWSサービスの第一レイヤーを受け持っている。過去にはエッジエンジニアリングに運用専任のチームとデプロイ+運用+サポートを担当するSREが存在していた。新機能リリース時は開発チームと運用チームがメトリクス、アラート、キャパシティープランニング等についての調整を行い、その後デプロイと運用のため開発チームから運用チームにコードが手渡されていた。コードの運用とパートナーのサポートを効果的に行うために、運用チームは新機能やバグフィックスについての継続的なトレーニングが必要だった。開発チームとは分離した運用チームを持つことの主な利点は、物事が上手くいっているときは開発チームへの割り込みが少ないことだ。
しかし上手くいかなくなるとコストは積み上がっていく。開発チームと運用チーム間でのコミュニケーションや知識の移転はロスが多く、デバッグやパートナーからの質問に回答するためには余計な往復を必要とした。また、運用チームがデプロイされる変更点についての直接的な知識を持っていないため、デプロイ時の問題の検知と解決にはより多くの時間がかかった。コードの完成からデプロイまでの時間は今よりずっと長く、リリースは日ではなく週単位で行われた。アラート/監視の欠如や性能問題やレイテンシーの増加といった問題で実際に苦しむのは運用チームで、開発チームはそれを運用チームから間接的に伝えられるだけだった。
この状況を改善するため、エッジエンジニアリングでは開発チームも必要なときにコードをプッシュでき、業務時間外の本番環境での問題やサポートも行うというハイブリッドモデルが導入された。これにより開発者のフィードバックと学習のサイクルは改善された。しかし部分的に責任を負うだけでは、チーム間の溝は埋まらなかった。
例えば、開発チームがデプロイをしたりパイプラインの破損をデバッグできたとしても、多くの場合彼らはリリースの専門家である運用チームの指示に従うことが多かった。また運用チームにとっては、日々の仕事を行うモチベーションはあっても、他チームから自身への依存をなくすための自動化を優先させるのは難しかった。
より良い方法を探し求め、私たちは一歩戻って第一原則から考え直した。何を達成すべきで、なぜそれができてないのか?
ソフトウェアライフサイクル
ソフトウェアライフサイクルの目的はtime to valueの最適化、つまり効果的にアイディアを実際のプロダクトやサービスに変換することだ。ソフトウェアサービスを開発し運用することは一連の責任から構成される。

ソフトウェア開発ライフサイクルのコンポーネント
私たちはこれらの責任を分割していた。極端な例ではそれぞれの機能が全く別の個人/役割によって担当されていたのだ。
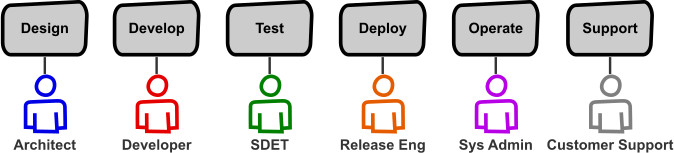
ソフトウェア開発ライフサイクルの専門家
これらの専門化された役割はそのセグメント内では効率的だが、ライフサイクル全体の非効率性を潜在的に作り出す。専門家は自分の分野での専門性の獲得や物事の最適化を行う。彼らは自分のパズルを解くことにより効果的になっていくのだ。しかしソフトウェアで顧客に価値を提供するためにはライフサイクル全体が必要となる。ライフサイクルの一断面のみを担当する専門家チームを持つとサイロ化が進み、最終的な顧客への価値提供を遅らせることになる。異なる分野の専門家を1つのチームにすることでサイロを減らすことができるかもしれない。しかし1つのチームで別々の専門家が自分の仕事を行うような状況では、コミュニケーションのオーバーヘッドの増加、ボトルネックの発生、フィードバックループの非効率性に繋がってしまう。
開発したものが運用する
devopsの原則は私たちのアプローチを考え直す際にインスピレーションを与えてくれた。サイロを解体しフルソフトウェアライフサイクルの共同所有を奨励することで、学習とフィードバックを最適化することができる。
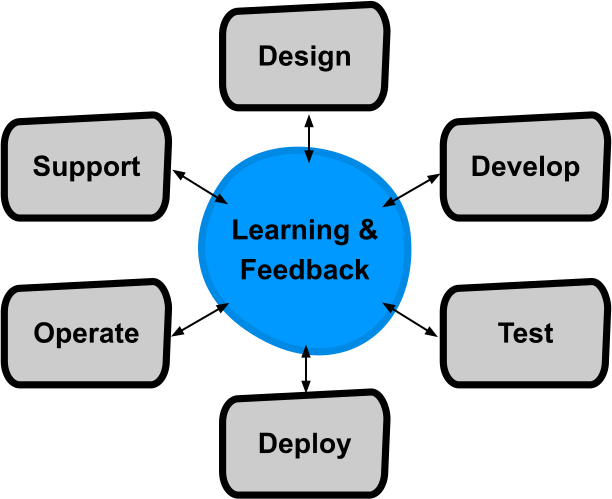
devopsの原則を取り入れたソフトウェア開発ライフサイクル
"開発したものが運用する"というアプローチでは、システムを開発するチームが運用とサポートにも責任を持つことでdevopsの原則を実践する。責任を外部化するのではなく開発チームに与えることで、ダイレクトなフィードバックループと共通のインセンティブを持つことができるのだ。運用に苦痛を感じているチームにはシステムの設計やコードを変更することでそれを治癒する力が与えられる。彼らは開発と運用の両方に対して責任を持っている。各開発チームは開発上の課題、パフォーマンスのバグ、キャパシティープランニング、アラートの欠如、パートナーサポートといったものを受け持っているのだ。
開発者ツールによるスケール
一連の開発ライフサイクルに対するオーナーシップによりソフトウェア開発者に求められることは大幅に増えるが、開発上の共通する要求を単純化したり自動化するツールによって負荷を軽減できる。例えばソフトウェア開発者がサービスのロールバックの管理することになる場合、ロールバックができるだけでなく問題の検出やアラート通知ができる高機能なツールが必要になる。
Netflixでは、多くの開発チームが持つ共通の課題を解決するためのツーリングとインフラの開発をミッションとする複数の集中型チーム(e.g. クラウドプラットフォーム、パフォーマンス&リライアビリティエンジニアリング、エンジニアリングツール)が創設された。このチームは専門化された知識を再利用可能なビルディングブロックにすることにより他のチームの力を高める。
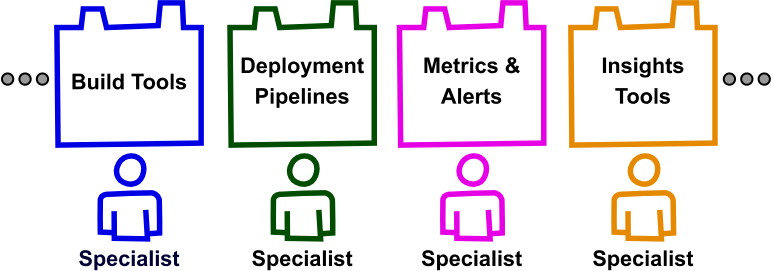
専門家が再利用可能なツールを作る
これらのツールを手中にして、開発チームはプロダクトのドメインの問題解決に集中することができる。新しいツールへの必要性が生じたとき、集中型チームは、複数の開発チーム間で共通のニーズがないか見極める。そして共通のニーズと認められたら、共同作業が進められる。開発チームからの要望が特殊すぎて共通の投資としては認められないこともあるだろう。その場合、開発チームはその課題が自分たちで解決するほど重要なものかを判断することになる。
類似した課題への対応を共通投資とするかしないかを判断することは、私たちのアプローチで最も困難なことの1つだ。私たちの経験では、複数のグループが最終的に1つになるような解決策を並行して作ってしまうリスクを冒してでも、開発者からの要望に対して新しい解決策を発見することは価値がある。コミュニケーションと目的の共有は成功への鍵だ。まずは要望を理解しそれが汎用的あるのか判断することで、Netflix全体の開発チームにとってより良い投資をすることができる。
フルサイクル開発者
これら全てのアイディアをまとめることで、私たちは1つのモデルに到達した。驚くべき開発ツールを持ち、設計、開発、テスト、デプロイ、運用、サポートといったフルソフトウェアライフサイクルへの責任を持つ開発チームだ。
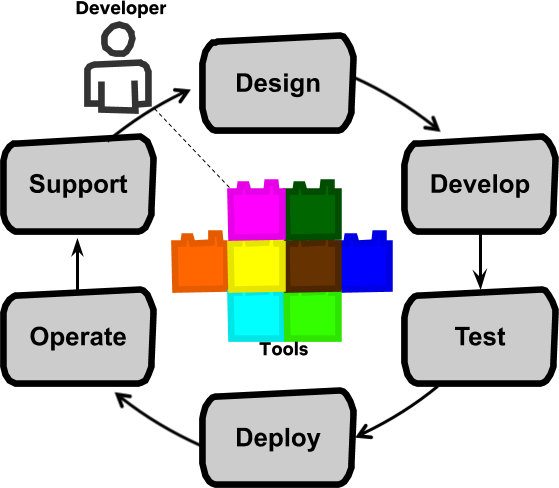
エンパワーされたフルサイクル開発者
フルサイクル開発者はソフトウェアライフサイクルの全ての分野において知識があり効果的であることが期待される。多くのNetflixの新入社員は自分が経験の浅い分野にも挑戦することになる。そのため知識の習得やスキルアップのための開発ブートキャンプと継続的トレーニングが用意されている。しかし知識だけでは十分ではない。容易に扱うことができるデプロイパイプラインツール(e.g. Spinnaker)やモニタリングツール(e.g. Atlas)も効果的なフルサイクルオーナーシップには必須なのだ。
フルサイクル開発者はエンジニアリングの原則をライフサイクルのあらゆる分野に応用する。開発者の視点で問題を評価し、「このシステムを動かすために必要なものをどう自動化できるか?」「どのようなセルフサービスツールがあればパートナーが開発者の手を借りずに自分の疑問に答えることができるだろうか」と問う。人間中心よりもシステム中心に考え、手動で行われていたものを自動化することによって、チームはスケールする。
フルサイクル開発者モデルを取り入れるには考え方を変えることが求められる。ある開発者が活躍の場として主に設計と開発、そして時々はテスト、と考えたとしよう。この見方は運用を邪魔者とみなし、"本当の仕事"に早く戻るために運用やサポートの問題に対して短期的な視点での対応をすることに繋がる。しかし、フルサイクル開発者の"本当の仕事"はライフサイクル全てにわたる問題を解決することだ。フルサイクル開発者はSWE(Software Engineer)としてもSDET(Software Development Engineer in Test)としてもSREとしても振る舞うのだ。あるときはビジネスの課題を解決するソフトウェアを開発し、またあるときはテストケースを書き、そしてまたあるときはシステム運用の自動化を行う。
このモデルを成功させるためには、チームはそれが価値あるものになるよう真剣に取り組む必要があるし、コストについても意識的でなければならない。ビルドとデプロイを管理し、本番環境での問題に対応し、パートナーからの依頼に応えるために、チームは余裕を持って配置される必要がある。トレーニングするための時間やツールへの投資も必要だ。再利用可能なコンポーネントやソリューションを生み出すために集中型チームとのパートナーシップも構築されなければならない。計画と振り返りではライフサイクルの全ての分野について検討しなくてはならない。アラート対応の自動化やパートナー向けのセルフサービスツールの開発は、ビジネス上の要望と同じレベルで優先順位付けされる必要がある。十分な人員と優先順位付けとパートナーシップによって、チームは自分のビルドしたものを運用することができる。それなしにはチームは過度な負担や燃え尽きのリスクに晒されることになる。
Netflix以外でこのモデルを採用するには調整が必要だ。開発チームによくある課題は似通っている。例えば継続的デリバリーのためのパイプラインが必要だったり、モニタリングだったりするだろう。多くの企業ではNetflixのように集中型チームに対して人員を配置できないだろうし、Netflixの規模が必要とするような複雑性も不要だろう。Netflixの多くのツールはオープンソースだし、手始めに試してみるにはちょうどいいだろう。まずは潜在的な価値やコストの分析から始め、続いて考え方を変えてみよう。何が必要かを評価し、最小のコストでどう実現するかを考えよう。
トレードオフ
テック業界には開発と運用上の要求を解決するための多くの方法が存在する(devopsトポロジーを参照)。ここで記述したフルサイクルモデルはNetflixでは普通のものだが、マイナス面もある。あるモデルを選択する前にそのトレードオフを知ることは成功の確率をあげることになるだろう。
フルサイクルモデルにおいては、ツールによって拡大されたより広い分野でのオーナーシップや有効性に対して優先順位付けがなされる。仕事の幅広さは多様なテクノロジーへの興味や適性を求めることになる。あるエンジニアは狭い分野での世界的な専門家になることを好むし、そのような専門家が必要とされる分野もある。このような専門家にとっては、広い分野でそれなりのスキルを求められることは居心地の悪いことであるし、時には虚しいと感じるかもしれない。Netflixでも、幅のあるスキルではなく特定の分野での深い専門性を好む人々も存在するし、私たちもそのような働き方をサポートしている。そして別の人たちはより幅広い職務を楽しみながら働いている。
クラウドシステムの開発と運用を行う中で、私たちはフルサイクルであることを重視する開発者が如何に効果的に働くかを知った。しかし、その幅広さは開発者の認知的負荷を増大させるし、チームは1つの分野にフォーカスしてる場合より頻繁な優先順位付を行うことになる。これはデプロイ+運用+サポートを順番に担当するオンコールのローテイションを組むことで緩和することができた。上手くいっているときは集中してフロー状態で仕事をすることが可能になるし、上手くいかないときは割り込みだらけの環境でなり、それは結局燃え尽きにつながることになる。
ツールと自動化は専門知識をスケールすることができるが、開発者の生産性と運用についての全ての問題を解決するツールというのは存在しない。Netflixには集中型チームにより正式に管理された一連の"舗装された(paved road)"ツールとプラクティスがある。私たちはこれらの"舗装された"ツールを採用することを強制はしないが、これらのテクノロジーを使うことでずっと良い開発と運用を行えることを確認しているので採用を推奨している。しかし、私たちのアプローチのマイナス面として「最も重要な要求のための全ての機能を積んだ全てのツールを全てのチームが使ってる」という理想が殆どの実現不可能だということがある。私たちの集中型チームへの投資に対するリターンを実現するのには、努力と共通理解と継続的な適応が必要なのだ。
結論
2012年から今日までの道のりは実験と学習と適応の連続だった。エッジエンジニアリング——その早期の実験はより良いモデルの探求に繋がった——は今日のフルサイクル開発モデルに応用されている。デプロイは頻繁に繰り返されるルーティンになり、カナリアリリースは数日ではなく数時間で行われ、開発者はチーム間で責任を押し付け合うのではなく素早く問題の調査をして解決することができる。他の組織でも同様の恩恵が期待されるだろう。しかし、私たちは異なる場所から適用と学習によってここに到達したことを忘れてはならない。明日の要望がさらなる進化を導くだろう。
このモデルが実際に動いているところが見たい?未来に向けてこのアプローチがどう進化するかについての探求に参加したい?応募お待ちしています。
Philip Fisher-Ogden, Greg Burrell, and Dianne Marsh
arimura 訳
この記事は社内のGitHubに共有された下書きに対して、有志のメンバーがフィードバックするという形で翻訳されました。 翻訳に協力してくれたアミン、海老原さん、小橋さん、 t-wadaさんに感謝!