




Zucksでデータエンジニアをやっている pei です。
2023年6月26日から29日にかけて、Snowflake SUMMIT 2023がラスベガスで開催されていました。
CARTAでは昨年頃から重要なワークロードでSnowflakeを使っています。
今後の活用を推進する上で、最新情報に触れることや世界のトッププレイヤーが何を考えてデータと向き合ってるかを肌で感じるために参加致しました。

Snowflake SUMMITとは
イベントページに書いてある「The World’s Largest Data, Apps, and AI Conference」のままですが、最大規模のデータ系のカンファレンスで、データに関するアプリケーション、もちろんAIに関連したトピックを中心に様々なセッションやハンズオンが用意されています。
当時の空気感に関しては、Twitter の方が臨場感があるので、そちらを御覧ください。
今回のSummitでは、様々な革新的なソリューションの発表がありました。それらの中で、個人的に重要だと感じたものについて、私の考察も交えてまとめたいと思います。
日本コミュニティで対談イベント
実は、日本コミュニティで、SUMMITが始まる前に現地でパネルディスカッションをしました。

www.youtube.com こちらが当時の録画です。
熱いトピック
ここからは、筆者が考える熱いトピックと、何故それが熱いかについて書いてみようと思います。
Container ServicesとNative Apps
Container Servicesとは、文字通りで、作成したコンテナ(≒アプリケーション)を、Snowflake上で実行できるサービスです。
つまり、実質何でも作れると言っても過言ではないです。
これまでは、Snowflakeはデータを集める場所であって、データで価値を出す(≒データアプリ)には、他のクラウドを併用する必要がありました。
今回、発表された Container Servicesの登場で、Snowflakeで価値提供まで完結が可能 になりました。しかも、このアプリは、外部に販売することもできます。
これまでの常識では、自社にあるデータとロジックを提供するには、追加で仕組みを構築し、顧客に提供する必要 がありました。よくあるのが、httpを使ったレポートAPIの提供などです。この方法には課題がありました。実装コストも当然ですが、ホスティングにかかるコスト、スケーリングに関してまで責任を持つ必要があり、データでの価値提供の本筋とは関係のないところにコストがかかります。
それが、 Native Appsの登場で大きく変化 します。
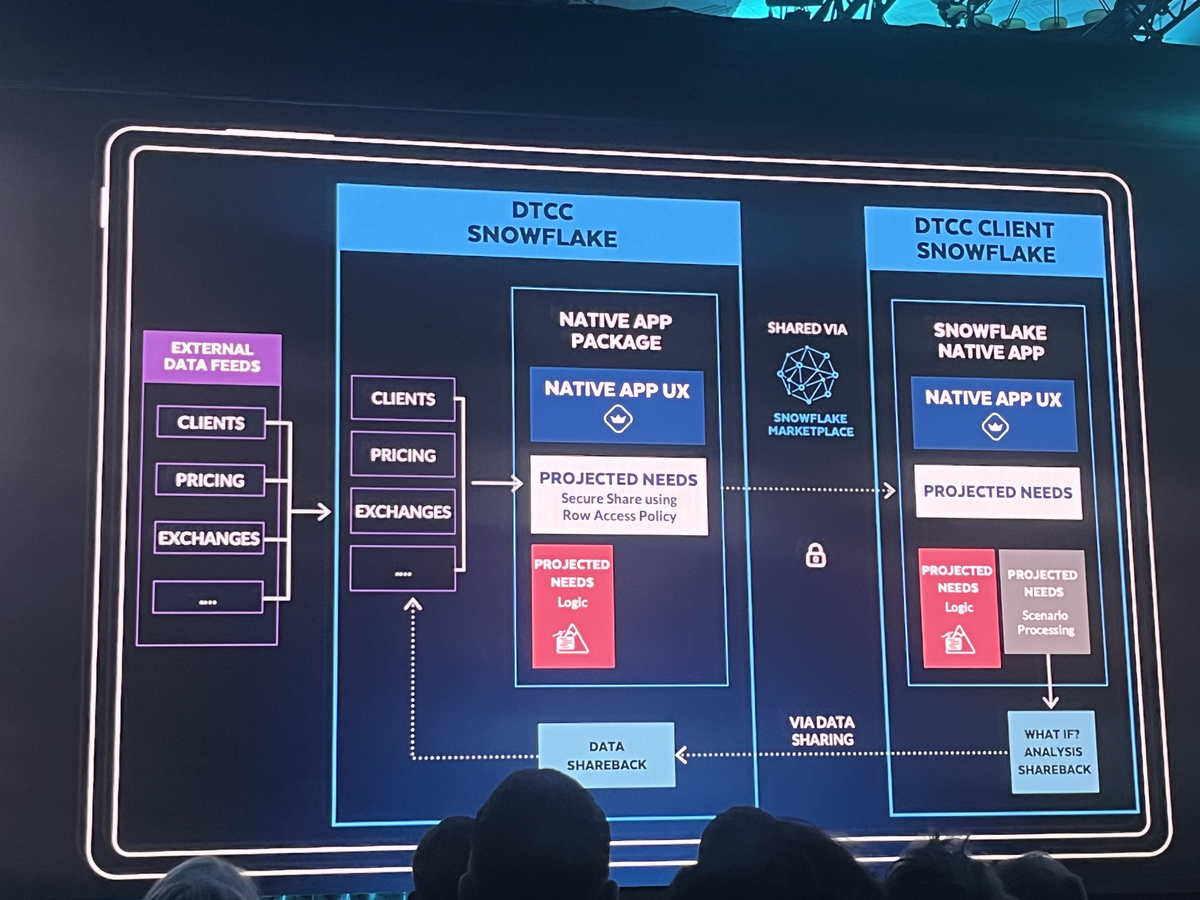
KeynoteでDTCC社による活用事例が紹介されました。
この会社では、データとロジックの提供をNative Appsを使うことで、どのように価値提供に繋げたかを話してくれました。
この図の読み方を軽く解説すると、アプリプロバイダーとしてDTCC社が、Native Appsを構築するために必要なパッケージを作ります。それをMarketplaceを通じて顧客に提供し、顧客のSnowflakeアカウントでNative Appsを展開しています。
以下、DTCC側のようなNativeAppsの提供者をプロバイダー、NativeAppsの提供先をアプリ利用者とします。
これの何がすごいのか?
まず、コンピューティングリソース(≒ウェアハウス)がアプリ利用者のアカウントで管理している点です。
例えば、http APIで提供していた場合には、そのAPIの提供ためのリソースをプロバイダーが管理する必要がありました。これには一定のコストが常にかかります。しかも、アプリ利用者によって必要なリソース量は違ったりします。
しかし、Native Appsの場合、必要なリソースを必要なだけ、アプリ利用者側で設定すればいいだけ です。
次に、データをセキュアに保ちつつ、シェアリングが実現できている点です。

アプリ利用者に提供したいデータをNative Appsを通じて提供し、逆にアプリ利用者からデータを提供してもらうこともシームレスに可能 になっています。
仮に同等のことをやる場合、これまでは、それぞれが持つファイルサーバーやオブジェクトストレージを通じて、データを提供し合う方法や、どちらかが自社のデータにアクセスするための権限を相手側に渡したり、けど、これには問題があります。まず、データを外に持ち出してはならないケースが会社によってはあると思います。また、そもそも、このような仕組みは、非常に手間がかかります。
それが、素直にSnowflakeの権限調整だけで実現ができてしまう わけです。
また、これに加えて マネタイズをする方法もセットで用意 されています。

例えば、様々な人が困っている課題を解くようなネイティブアプリを構築したとします。それをマネタイズすることができます。めっちゃ夢ありますよね?
しかも、先程説明した通り、ホスティングする仕組みを用意する必要はありません。あなたは、便利なパッケージを作って配布するだけです。
2日目のKeynoteの最後に、NativeAppsで作られた各社のイケてる10個のデモが紹介されたんですが、会場が相当ざわざわしてたのは爽快 でしたね。
私もこれを見てめっちゃ夢あるじゃんって思ったので、
うおおおおおおっ
て叫んでました。

この内容に興味がある方は、是非以下も読んでみてください。
www.snowflake.com
Document AIで非構造化データ(PDF)を構造化する
昨今世間を騒がせているみんな大好きAIですが、Snowflakeから独自の大規模言語モデル(LLM)としてDocument AIが登場 しました。
以下の動画で、どのような挙動をするかが動くサンプルで見ることができます。
すごい簡単に説明すると、PDFのままSnowflakeにアップロードして、自然言語で問い合わせ をしています。
動画の中で、自然言語で質問を投げ、精度を表すscoreと該当箇所の値が取得できる様です。

あとは、SQLを書くだけ。

世の中には、PDFを始めとしたデータウェアハウスで、扱いやすい状態ではないデータがたくさんあります。それらを構造化できる可能性を示しています。
つまり、データエンジニアリング可能な領域が一気に広がる可能性があるわけです。これはめっちゃ熱い。
プログラマビリティとDevOpsの強化
Snowflakeの活用が進めば進むほど、プログラミング言語のサポートや、機械学習ワークロードへの対応、開発体験の向上、可観測性(オブザーバビリティ)が必要になるわけですが、今後広範囲に強化されていく様です。

以下に、詳しいことがまとまっているので、是非読んでみてください。
www.snowflake.com
可観測性の現状と将来
個人的に可観測性は、大事なトピックです。
可観測性とは
システムやアプリケーションの出力、ログ、パフォーマンス指標を調べることにより、その状態を監視、測定、理解する能力を指します。
データにおける可観測性は、根本原因分析、データリネージ、データの健全性に関する洞察の提供、データの異常性の検出、防止などです。 これらを実現することで、データパイプラインは健全化され、チームの生産性の向上、リードタイムの短縮が実現されます。
データドリブンに寄れば寄るほど、データの信頼性が重要になります。意思決定に使っているデータが、そもそも信用できなければ本末転倒なので当然です。
データに関連した可観測性において、例えば、あるデータが0件を示してるとします。このとき
- バッチ処理が遅れていて0件なのか
- Snowflake起因で0件になっているのか
- クエリが間違えていて0件なのか
- ログを作り出すアプリケーションに問題が起きて0件なのか
- 本当にデータが存在してなくて0件なのか
を知るのは簡単ではありません。
こういった複雑な世界から真実を知るには、可観測性が高いことは重要です。
もちろん全てSnowflakeがカバーできることではありませんが、Snowflakeで何が起きているかを知ることが、簡単なことは重要です。
実は現状用意されている機能だけでも、観測することは可能ですが、正直、頑張って出来るみたいな世界線を脱していません。
今後やりやすくなるアイデアが実装されることを期待したいです。
日本コミュニティでWrap up会
実はSUMMIT終了後に、日本コミュニティでWrap up会がありました。そこにSnowflake 共同創業者Benoit氏が来てくれました。せっかくなので、この話題に関して彼に聞いてみました。
pei: 「今後、Snowflakeとして可観測性に関する投資をする予定はあるか?活用すればするほど、観測のしやすさは重要になるので、どこまで機能が充実するのか気になっています」
と質問したところ、
Benoit: 「とても重要なことなので、今後機能を充実させる予定はある。他のお客様からも同様の要望は多数受けており、課題と認識している」
とのことでした。
もちろんすぐに劇的な変化が起きるわけではないでしょうけど、President of Productsからこのような回答を貰えたのは、色々な意味で期待を持てました。

オフラインで参加する価値
昨今では、様々な情報がオンライン上で得ることが可能になりました。そんな状況で、わざわざ現地に行く価値があるのか?
ちなみに、参加費は早期購入割引(アーリーバード)で、1,795ドルしました。当時のレートが1ドル145円なので、軽く25万程いきます。しかも、そこに 旅費が様々かかる上に、私という人件費もかかります。
その上で、私は行った分、大きなリターンが得られたと感じています。 それについて、ちょっとまとめてみます。
スピーカーから、直接話を聞ける
Keynoteとは別に、セッションやハンズオンが数多くあります。
そこで、直接スピーカーに話を聞けます。また、同じ人間がこんなことやってるのか・・・というのを解像度高く感じることができます。
あとは、シンプルに普段は絶対話す機会がない人たちなので、とても貴重な出会い になります。
英語が苦手?大丈夫です。スマホに聞きたいこと英語で書いて聞きに行けば、わりと答えてくれますw
集中して、インプットに取り組める
これは、もしかしたら、私だけかもしれませんが、 カンファレンスの録画があるからと言って、目の前の仕事をそっちのけで、録画を集中して見るのは結構難しい です。
出張という形で、現地に行けば、多額のお金がかかってる分、やはり一定の緊張感があります。
何か持ち帰らなければと思うのもあり、高い集中力でセッションに臨めます。 そこで、これまでキャッチアップが漏れていたトピックをまるっとインプット可能なので、密度の高い学習が可能 になります。
また、SUMMITではSnowflakeがこれから何を目指していくのかを知れるので、帰国後の学習にも良い影響がある と思います。
ワクワクする
コミュニティの人たちと、データに関する将来についてディスカッションしたり、帰ったら何をしようを話したり、そこから得られるワクワクはやっぱり段違いです。
録画観てるだけだと、こういう感情になるのは難しいです。
さっき観たアレやばくね?
を話せる人たちが集まると、やっぱり話すのはとても楽しいです。
まとめ
全体を通しての感想としては、ワクワクと焦りが半々でした。
率直に言って、Snowflakeとトッププレイヤーたちの進化が早すぎて、全くそのスピード感に追いつけてないので、焦りました。
一方で、まだまだやれることはいくらであるとも知れましたし、ここにもっと投資をしていこうという気持ちをになりました。
