



こんにちは、システム本部データプラットフォームグループ(DPG)エンジニアのEthan Huです。
今回はECナビ(http://ecnavi.jp/)で使用しているレコメンデーションシステムについてご紹介します。
ECナビでのレコメンデーションシステムの利用方法は、ユーザ1人1人に合わせた情報配信を行う事を目的としています。この様なシステムの導入時、社内でも話題に上がるのが「そもそもレコメンデーションシステムって効果あるの?」の声です。
また、レコメンデーションシステムは様々な手法(アルゴリズム)があり、正直どれが良いか検証しないとわからない所が大きいです。
今回は各アルゴリズムの評価、効果検証も考慮したレコメンデーションシステムの構成について紹介します。
レコメンデーションアルゴリズムについて
その前に、レコメンデーションの手法を簡単に説明します。
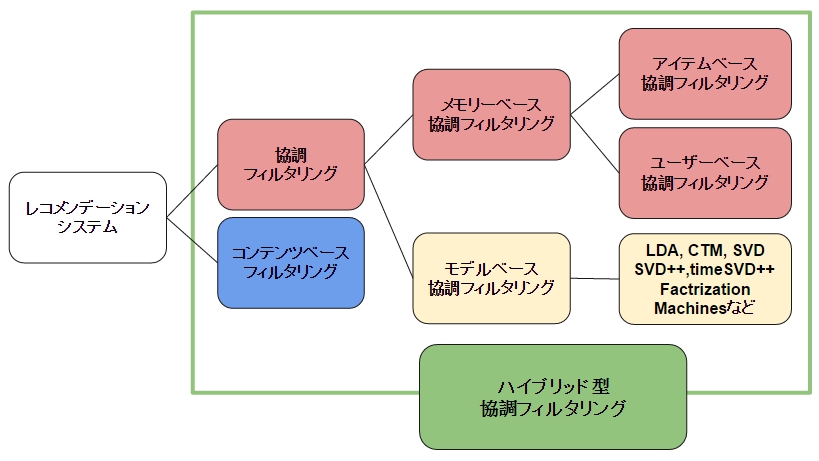
レコメンデーションアルゴリズムとして「協調フィルタリング」があります。
協調フィルタリングには大きく分けて、メモリーベース(ユーザ行動履歴)とモデルベース(機械学習等の手法)に分けられ、メモリーベースはアイテムベース(アイテム間の類似度を元に推薦)とユーザベース(ユーザ間の類似度を元に推薦)に分類できます。
ECナビのレコメンドシステムは協調フィルタリングになります。
レコメンデーションシステム構成
ECナビのレコメンデーションシステムでは、メモリーベース・モデルベースの両方のアルゴリズムを使用しています。その為、検証したいアルゴリズムパターンが30個近くなります。
また、今回の構成では、複数のアルゴリズムを同時に検証でき、且つアルゴリズムの追加・更新をしやすい構成を取っています。
検証方法は複数のアルゴリズムを同時に検証できるようユーザのサンプリングを行い、サプリングユーザvs各アルゴリズムパターンでの多変量テストを実施してます。

上図がざっくりとしたシステム構成です(かなりざっくりですが)。レコメンドシステムはオンプレとクラウド(AWS)を使用したハイブリッドな構成です。
簡単に各処理の説明を書きます。
データクレンジング(前処理)
ETLサーバでは、学習データの元になるデータの前処理を行ってます。データの前処理後、DWHにLoadします。ユーザサンプリング
各アルゴリズム検証用にユーザサンプリングを行います。サンプリングでは検証用のユーザが偏らないようにする為と、検証に必要なサンプルサイズを担保する為で、検証する際はとても重要なポイントです。学習データの作成
学習データは様々な特徴データを作成する必要がある為、DWHで集計→作成しています。データはログデータがベースになるため、大規模な集計になります。推薦データの作成
各アルゴリズムによって学習データから実際に推薦データを作成する方法は様々です。メモリーベースの推薦の場合、DWHで推薦データ処理を行なっていますが、モデルベースの場合AWS EMR(Apache Spark)で処理しています。
レコメンデーションのチューニング
レコメンデーションシステムの実装・リリースは完了しましたが、各モデルの精度をさらに向上させるためチューニング作業を行います。
チューニング作業の一般的な流れは以下のようになります。
- モデル実装
- 検証(2週間 ~ 1ケ月頃)
- 結果FB
- モデル最適化調整
- 上記 1 ~ 4 を繰り返す
まとめ
この記事では、ECナビで実装したレコメンドシステムについて、おおまかに構築した仕組みについてまとめしました。
実際に検証、利用しているモデルや、その特徴量、パラメータの値については、システムのキモとなるのでブログに載せることはできませんでしたが、ざっと10~30近くのモデルを随時検証・走らせています。
実際レコメンドでの効果は、CTRが1.8倍、CVRで4倍位出てます。
また、高速化を求めてSparkのチューニングも頑張っています。
この辺に興味のある方は、ツイッター(@tech_voyage)に気軽に連絡をください。#ajitingしましょう! そして、ECナビでは仲間を募集しています。 http://voyagegroup.com/crew/recruit/career/
Reference
http://www.kamishima.net/archive/recsysdoc.pdf
https://www.moresteam.com/toolbox/design-of-experiments.cfm