



こんにちはこんにちは!株式会社 fluct で Web 広告配信のお手伝いをしている @jewel_x12 です!
本記事は Redash が便利という内容です。
Redash とは
Redash とは Web ブラウザから様々なデータソースに対するクエリを投げて、結果を可視化する OSS になります。 Redash には便利な機能がいくつか機能があるのですが、数点挙げると
- 様々なデータソースへの対応
- クエリの定期実行とアラーティング
- Slack などへの投稿
- クエリ結果のキャッシュ
- Google OAuth などいくつかの認証サービスでユーザー管理ができる
あたりです。
弊社では Redash が広く導入されており、エンジニアなどの職種に関わらず利用者がいます。BigQuery のクエリへ Quota をかけられたり、機微な情報のあるテーブルへアクセス制限できるところなどが誰でも気軽に利用してもらえるところかもしれませんね。
個人的にメチャ推しなポイントは様々なデータソースへの対応です。サポートしているデータソースの一覧を見ていただければ分かるのですが、MySQL や AWS の DB 系サービス、BigQuery や ElasticSearch などにも対応しています。Redash をハブとして、散らばりがちなデータソースへ1箇所からアクセスできるようになるのが便利です。
Jupyter Notebook から Redash を使う
さて、自分は広告ログ周りのデータを見ることがあります。解析結果の可視化やレポーティングは Jupyter Notebook を利用しています。Jupyter Notebook はコードのインタラクティブな実行環境であり、Python などのコードをセルという単位で処理したり可視化したりできます。実行結果はいくつかの方法で export 可能であり、グラフなどを共有するのにも役立ちます。私は Jupyter Notebook をベースとした Google Datalab の Docker コンテナを起動して利用しています。Google Datalab を使用しているのは、はじめ BigQuery だけ使用することを考えており BigQuery アクセス用ライブラリなどが最初から使えるので利用していました。*1
実際は各種 ID などを他のデータソースと JOIN したくなるケースが多く、MySQL などのデータソースも利用したくなりました。Jupyter Notebook から MySQL への接続は可能ですが、接続用パスワードの管理があったり、他のデータソースが増えてくると各クライアントの初期化や使い分けが煩雑になりそうだったので、Redash をハブとしてクエリを投げるようにしてみました。とりえあず Redash へクエリを投げることができればデータソースはなんでも良くなります。弊チーム内ではある程度のユースケースはカバーできそうでした。
Redash API Client
Redash にはクエリを実行したりする API があるので、 Jupyter Notebook からは簡単なクライアントを書いて利用しています。
Jupyter Notebook ではこのクライアントからの結果を pandas.DataFrame へ変換するラッパーをスタートアップスクリプトに書いています。
from redquery import Client host = 'https://redash.host.example' myr = Client(host, api_key, mysql_datasource_id) bqr = Client(host, api_key, bigquery_datasource_id) def mquery(q): return query(myr, q) def bquery(q): return query(bqr, q) def query(client, q): res = client.query(q) return (pd.DataFrame(res.rows), res)
api_key は Redash のユーザー画面に API Key というタブがあるのでそちらを利用しましょう。datasource id が admin ユーザー以外には分かりにくいのですが、てきとうなクライアントを作って client.data_sources() とかやるとデータソースとデータソースIDの対応を取得できます。
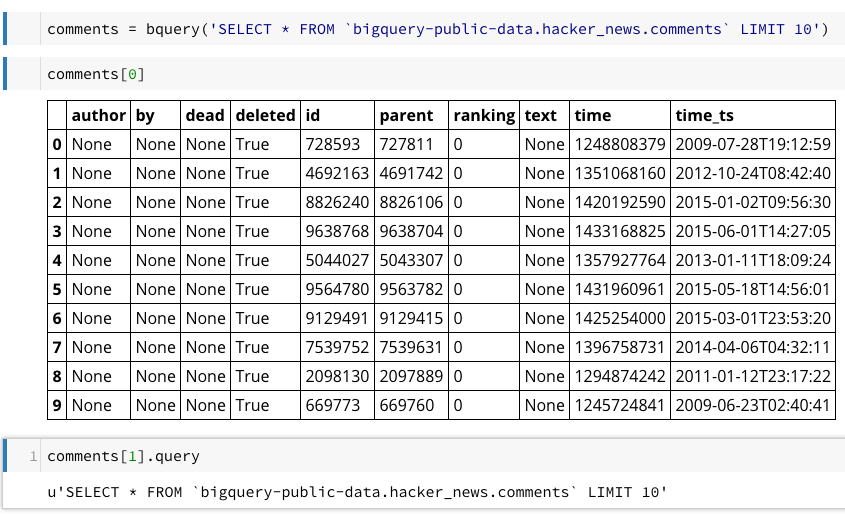
クエリエラーも分かります。
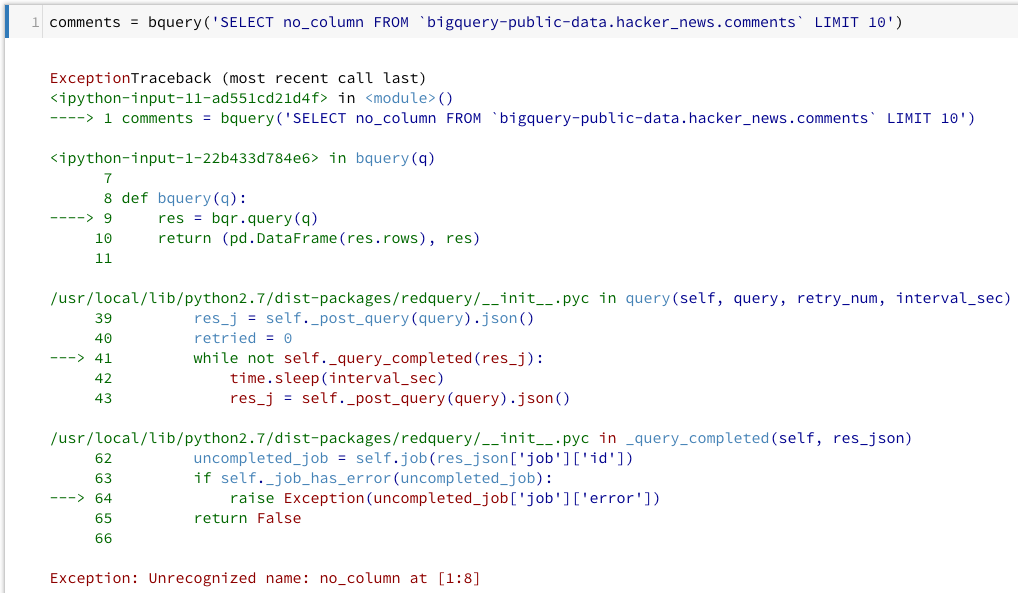
これで Redash とつながっているデータソースに対してクエリを投げられるようになりました。 といってもまだ MySQL や BigQuery でしか試していないので、他のデータソースだとうまく動作しない可能性があります。
それにしても API Key ひとつで異なるデータソースへクエリが投げられるのは、なかなか便利です!
おまけ
Redash を長く運用していると、過去に設定した定期実行クエリがずっと動いているというようなことがあります。 BigQuery で定額料金ではない場合など、クエリ毎に課金が生じるタイプのクエリは定期的に棚卸ししてあげるとコーヒー代くらいは浮くかもしれません。
scheduled_queries = [ q for q in client.all_queries() if q['schedule'] ] for q in scheduled_queries: print("http://redash.host.example/queries/%d\t%d\t%s\t%s\t%s\t%s" % (q['id'], q['data_source_id'], q['name'], q['schedule'], q['created_at'], q['user']['name']))
*1:ちなみに Datalab のサービスを利用せずコンテナを起動して利用しているのは解析結果を GitHub の nbviewer 機能で共有するためです。解析結果を共有したい相手が Google Datalab を動かすための VM インスタンスを立てられる人ばかりではないのと Jupyter Notebook 自体を触る人はそんなに多くないので、実行環境は各自が用意すれば良いという観点から、Github アカウントを作ってもらい共有するほうが楽だと考えました。Google Cloud Source Repositories にそのような機能があると Google アカウントだけでよくなるので嬉しい……